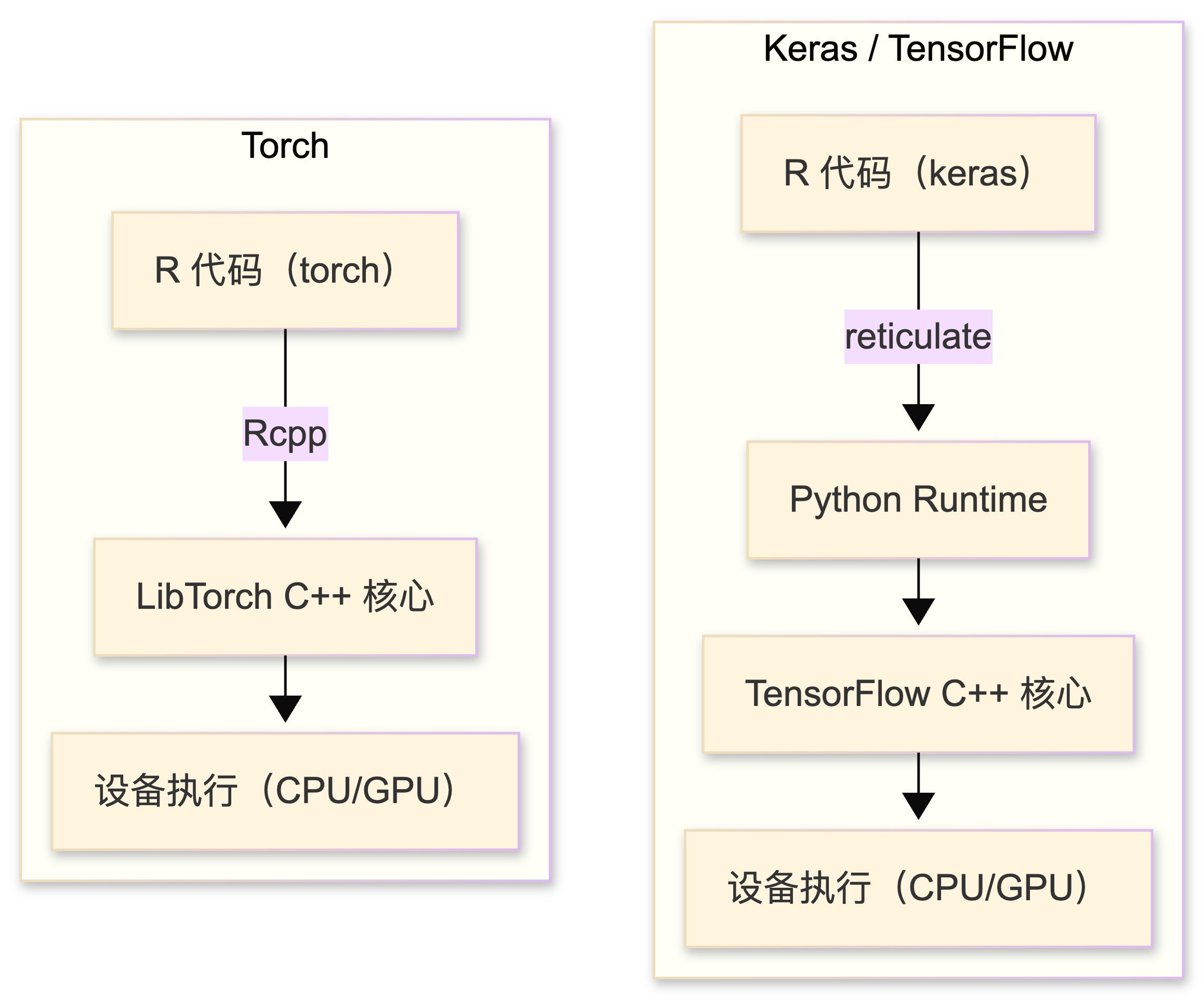
torch (Falbel 和 Luraschi 2025 ) 包是一个为 R 语言习惯量身定制,直接构建在 C++ 的 LibTorch 之上 的原生深度学习框架。
本课程使用 torch 作为核心工具,正是看重其在“算法透明度”与“工程直觉”之间的完美平衡:
torch 坚持使用 R 的 1 起始 (1-based) 索引。这意味着当你面对数学公式中的 \(x_1\) 时,代码里就是 x[1] 而非反直觉的 x[0]。这种微小的一致性,极大地降低了将公式转化为算法时的认知负荷与高度封装、隐去细节的高级框架不同,torch 鼓励通过 nn_module 手动编写 forward 函数。配合动态计算图(Dynamic Graph),你可以像操作原生矩阵一样随时暂停、检查张量维度、观察梯度流动。这让深度学习不再是不可捉摸的黑盒,而是触手可及的数值演算。
本课程将从传统统计回归开始,讲解自动微分的机制,最终以工业界非常典型的变现业务推荐系统为例,讲解召回模型。让同学们体会“优雅的”数据处理 tidyverse、统计绘图 ggplot2、深度学习 torch,直至工程部署的闭环过程。同学们可以看到大量的管道操作 %>% 或 |> 的数据流和建模流。
从解析解到数值解
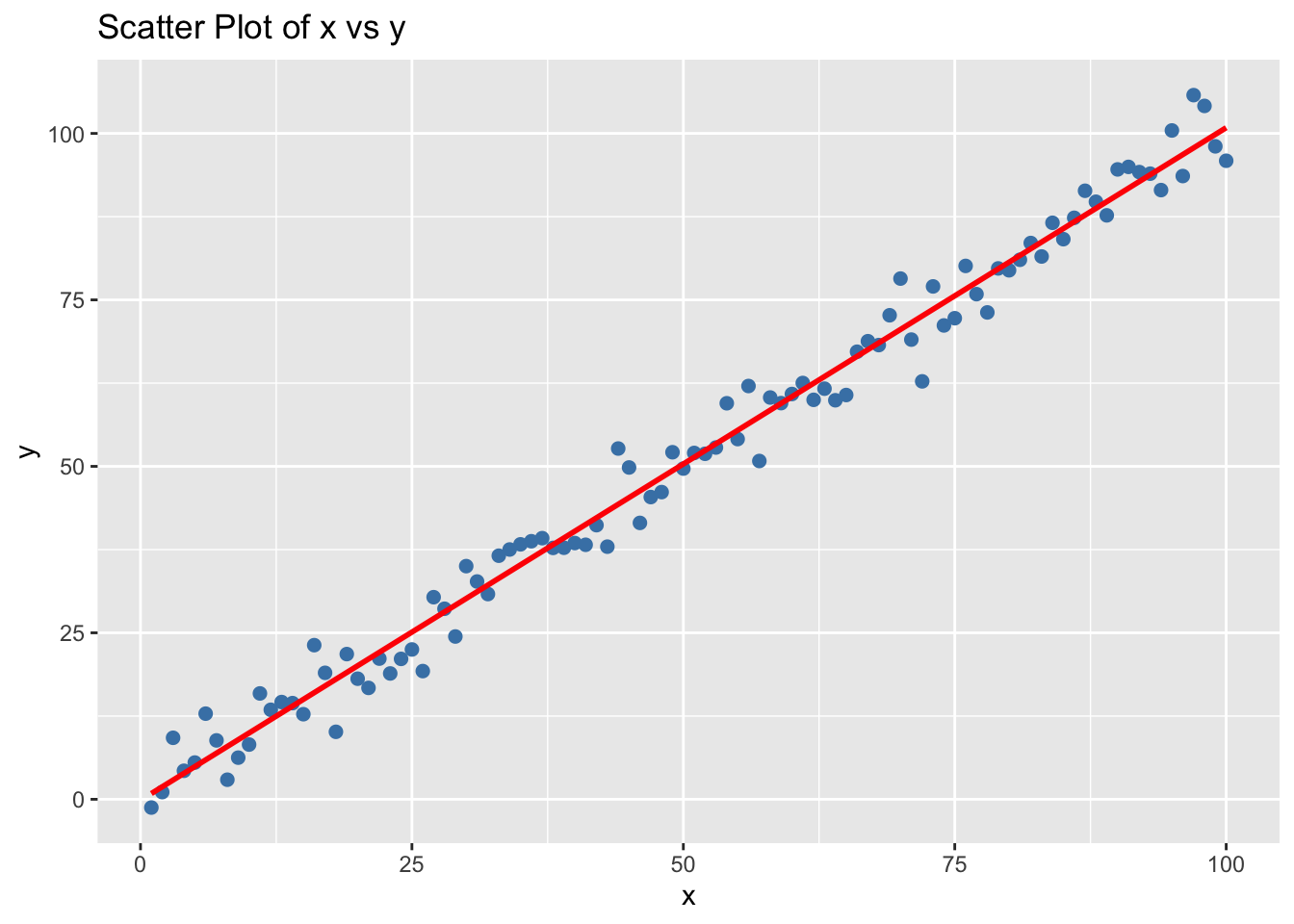
先是一个简单的一元线性回归,理解它在求解什么?
\[
\begin{aligned}
x_i &= i,\quad i = 1,2,\ldots,100, \\
y_i &= x_i + \varepsilon_i,\quad \varepsilon_i \sim \mathcal{N}(0,4).
\end{aligned}
\]
对应的代码和可视化代码:
set.seed (123 )<- 1 : 100 <- x + rnorm (100 , 0 , 4 )library (ggplot2)ggplot (data.frame (x = x, y = y), aes (x, y)) + geom_point (color = "steelblue" , size = 2 ) + geom_smooth (method = "lm" , formula = y ~ x, color = "red" , se = FALSE ) + labs ( title = "Scatter Plot of x vs y" )
对于熟悉 R 语言的数据科学工作者来说,下一步的操作几乎是肌肉记忆——直接调用 lm(y ~ x),瞬间就能得到最优的 \(\beta_0\) 和 \(\beta_1\) 。
<- lm (y ~ x)library (stargazer)stargazer (fit, type = 'text' )
===============================================
Dependent variable:
---------------------------
y
-----------------------------------------------
x 1.010***
(0.013)
Constant -0.146
(0.737)
-----------------------------------------------
Observations 100
R2 0.985
Adjusted R2 0.985
Residual Std. Error 3.658 (df = 98)
F Statistic 6,352.370*** (df = 1; 98)
===============================================
Note: *p<0.1; **p<0.05; ***p<0.01
先跑个题,\(R^2\) 大家觉得合理吗?
在解释回归模型好坏时,我们不能仅仅说“误差很小”,因为“小”是一个相对的概念(比如预测房价时的误差是几万元,预测身高的误差是几厘米,尺度完全不同)。\(R^2\) 的目的,是提供一个无量纲的、介于 0 到 1 之间的标准分数,用来衡量模型对数据的“解释力度”。
它背后的逻辑是“比较”。它将你的回归模型与一个“最笨的基准模型”进行对比。这个最笨的模型就是:无论输入什么,我都预测目标变量的平均值(Mean)。
总平方和 (SST, Total Sum of Squares): 真实值与平均值之间的误差平方和。这代表了数据中所有的波动(方差)。
残差平方和 (SSE, Sum of Squared Errors): 真实值与模型预测值之间的误差平方和。这代表了模型未能解释的波动。
\(R^2\) 的公式为:
\[
R^2 = 1 - \frac{SSE}{SST}
\]
通俗翻译 \(R^2\) :和那个只会猜平均值的“笨模型”相比,你的回归模型把预测误差缩小了百分之多少。如果 \(R^2 = 0.8\) ,意味着你的模型解释了目标变量 80% 的波动。
从这个公式上,我们看到了很多的假设:
\(R^2\) 假设用数据的平均值来代表数据的中心趋势是合理的。它假设数据的波动(也就是偏离平均值的平方和)就代表了数据包含的“总信息量”。解释了多少方差,就等于解释了多少信息。
在计算多重线性回归的 \(R^2\) 时,数学机制决定了只要你往模型里加自变量(哪怕是毫无关系的垃圾变量),\(SSE\) 只可能减小或不变,因此 \(R^2\) 永远只会增加。
# 定义计算 R 方的函数 <- function (y_true, y_pred) {<- mean (y_true)<- sum ((y_true - y_mean)^ 2 ) # 总平方和 (SST) <- sum ((y_true - y_pred)^ 2 ) # 残差平方和 (SSE) <- 1 - (sse / sst) # 计算 R 方 return (r_squared)<- calculate_r_squared (y, predict (fit))cat (sprintf ("手动计算的 R 方为: %.4f \n " , r2_value))
另外 \(R^2\) 可能会出现负数:
<- c (10 , 11 , 12 )<- c (100 , 101 , 102 )calculate_r_squared (y_true, y_pred_terrible)
意义是我用均值预测都比你好太多。
不管怎样,R 在假设条件下的所有设计近乎完美,包括“一行代码”出结果的这种方式。
然而,当我们跨入可微编程(Differentiable Programming)和深度学习的大门时,这个熟悉且优雅的“一行代码”突然消失了。取而代之的,是繁琐的循环、学习率设定以及梯度更新。
这种视角的转换,往往是许多传统统计建模者在初学深度学习时遇到的第一个“认知门槛”。为了弄清楚我们为什么要“舍近求远”,我们需要深入模型底层的求解逻辑。
在深入学习 R torch 的自动微分机制之前,我们需要先解决一个 R 语言老手最常见的困惑:我们为什么要通过编写循环、设置学习率来“训练”模型,而不是像调用 lm() 那样直接算出一个结果?
要回答这个问题,我们需要重新审视统计建模与深度学习在求解方法上的本质差异。
无论是经典的线性回归,还是深度神经网络,在回归任务中,我们的核心目标往往是一致的:最小化残差平方和(Residual Sum of Squares, RSS)。
也就是找到一组参数 \(w\) ,使得预测值与真实值之间的误差最小 (Hastie 等 2009 ) :
\[
\text{Minimize } L(w) = \sum_{i=1}^{N} (y_i - \hat{y}_i)^2 = \sum_{i=1}^{N} (y_i - X_i w)^2
\]
既然目标一致,为什么解决问题的方法会发生如此剧烈的变化?这取决于我们的目标函数有多复杂。
解析解
在 lm() 的世界里,我们可以直接通过数学推导找到最优解。
回忆一下微积分:函数的极值点通常出现在导数为 0 的位置。对于线性回归 \(L(w)\) 这样一个完美的凸函数,我们可以直接对 \(w\) 求导,并令其等于 0:
\[
\frac{\partial L}{\partial w} = -2X^T(y - Xw) = 0
\]
解这个方程,我们不仅不需要迭代,反而能直接得出一个完美的公式,也就是正规方程 (Normal Equations):
\[
w = (X^T X)^{-1} X^T y
\]
这就是解析解 (analytical solution),也被称为闭式解 (Closed-form solution) 。只要数据 \(X\) 和 \(y\) 给定,我们不需要试错,直接把数字代入公式,一步就能算出那个让 Loss 最小的完美的 \(w\) 。这正是 R 语言中 lm()、solve() 背后的逻辑:精确、直接、一步到位。
1 lm 函数出于数值稳定性的考虑,调用的也不是 \(\hat{\boldsymbol{\beta}} = (\mathbf{X}^T\mathbf{X})^{-1} \mathbf{X}^T \mathbf{y}\) ,而是带列主元的 QR 分解。这种分解方式可以动态选择最“健康”的列作为主元,避免了多重共线性和病态矩阵带来的数值不稳定,是现代线性回归实现中最常用、最稳健的求解方式。
我们以 R 内置的 mtcars 数据集为例,通过汽车的车重 (wt) 和 马力 (hp) 来预测 油耗 (mpg)。
\[
\text{mpg} = w_1 \cdot \text{wt} + w_2 \cdot \text{hp} + b
\]
为了确保后续手动实现的梯度下降算法能够快速收敛,数据标准化(Scaling) 是至关重要的一步。如果特征之间的尺度差异过大(例如 wt 约为 3,而 hp 约为 100),梯度下降会在寻找最优解时走弯路(Zigzag),导致训练极其困难。
# 选取特征与目标 <- mtcars[, c ("wt" , "hp" )]<- mtcars$ mpg# 标准化特征 (Z-score normalization) <- scale (x_raw)# 设计矩阵:加上截距列 <- cbind (1 , x_scaled) # 1 是截距项 <- y_raw# OLS 解析解:beta = (X^T X)^(-1) X^T y <- solve (t (X) %*% X) %*% t (X) %*% yprint (beta_hat)
[,1]
20.090625
wt -3.794292
hp -2.178444
# 等价于实现了 <- lm (y_raw ~ x_scaled)print (coef (fit_lm))
(Intercept) x_scaledwt x_scaledhp
20.090625 -3.794292 -2.178444
数值解
既然解析解这么好,为什么深度学习不用?主要有两个原因阻断了这条路:
解析解的核心是矩阵求逆 \((X^T X)^{-1}\) 。当数据维度极高(例如图像处理中 \(X\) 可能有几十万列)时,没有任何计算机能算出这个逆矩阵。
深度神经网络本质上是多层非线性函数的嵌套 \(y = f(g(h(x)))\) 。这种复杂的函数地形不再是一个简单的“碗”,而是充满了无数的山峰、山谷和马鞍面。在这种情况下,根本不存在一个简单的数学公式能直接算出最低点在哪里。函数的非凸性,这是更本质的原因。
因此,深度学习被迫放弃了“瞬间移动”,选择了数值优化(Numerical Optimization)。
我们不再试图一步算出 \(w\) ,而是采用迭代更新的策略。这就是著名的梯度下降 (Gradient Descent) 算法:
\[
w_{t+1} = w_t - \eta \cdot \nabla_w L(w_t)
\]
这个公式描述了一个动态的修正过程:
\(w_t\) (当前位置):我们在第 \(t\) 步时的参数值。\(\nabla_w L(w_t)\) (梯度方向):告诉我们 Loss 上升最快的方向(即“最陡峭”的上坡路)。\(\eta\) (学习率):这是步长,决定了我们每一步走多远。\(-\) (减号):既然梯度指向“上坡”,那我们就往反方向走(下坡),从而减小 Loss。
整个训练过程变成了一个循环:
先随机初始化参数 \(w_0\) 。
算出当前的梯度 \(\nabla L\) 。
利用上述公式更新,得到更新后的参数 \(w_1\) 。
重复上述步骤,直到梯度接近 0 或达到指定轮数。
这种方法,需要我们手动推导均方误差(MSE)关于参数的导数公式:
\[
\frac{\partial L}{\partial w} = \frac{2}{N} X^T (Xw + b - y)
\]
\[
\frac{\partial L}{\partial b} = \frac{2}{N} \sum (Xw + b - y)
\]
写成 R 代码:
set.seed (123 )# w: 对应 wt 和 hp 的权重 (2行1列) <- matrix (rnorm (2 ), nrow = 2 ) <- 0 # 超参数 <- 0.1 <- 80 <- nrow (x_scaled) # 样本数量 N # 开始训练循环 for (i in 1 : epochs) {# 1. 前向传播 (Forward Pass) <- x_scaled %*% w + b # 使用 %*% 进行矩阵乘法 # 2. 计算误差 (Residuals) <- y_pred - y_raw# 计算 Loss (仅用于观察,不参与运算) <- mean (error^ 2 )# 3. 手动计算梯度 (The Hard Part!) # 对应公式:(2/N) * X^T * error <- (2 / n_samples) * (t (x_scaled) %*% error)<- (2 / n_samples) * sum (error)# 4. 更新参数 (Gradient Descent) # 向梯度的反方向移动 <- w - learning_rate * w_grad<- b - learning_rate * b_gradif (i %% 20 == 0 ) {cat (sprintf ("Epoch %d: Loss = %.4f \n " , i, loss))
Epoch 20: Loss = 6.1994
Epoch 40: Loss = 6.0966
Epoch 60: Loss = 6.0953
Epoch 80: Loss = 6.0952
20.09062 -3.791592 -2.181145
运行这段代码,你会惊讶地发现,经过 100 轮简单的加减乘除,我们得到的系数与 lm() 的结果惊人地相似。
既然 Base R 也能做,为什么我们需要 torch?
请注意上面代码中的第 3 步——手动计算梯度。对于简单的线性回归,导数公式还是高中数学水平。但想象一下,如果我们要构建一个拥有 100 层、包含各种非线性激活函数(Sigmoid, ReLU, Tanh)的复杂网络,手动推导并编写每一个参数的导数公式将是一场噩梦。只要有一个公式推导错误,整个模型就会崩溃。
这就是深度学习框架存在的意义。接下来,我们将看到 Torch 最核心的魔法——自动微分(Automatic Differentiation)。它将把我们从繁琐的导数推导中彻底解放出来。
理解计算图
很多初学者最大的困惑在于:Torch 到底是怎么在“不知道”函数全貌的情况下算出导数的?
其实,自动微分(Autograd)并不是对着一个长长的公式 \(y = f(g(h(x)))\) 去推导全局导数。它采用的是“盲人摸象”策略:Torch 的 C++ 底层预先写好了所有基本算子(加法、乘法、指数、对数等)的“局部导数规则”。
加法节点:无论谁经过我,梯度都原样传递,乘以 1。
乘法节点:也就是 \(y = w \cdot x\) ,我对 \(w\) 的导数就是 \(x\) ,对 \(x\) 的导数就是 \(w\) 。
平方节点:也就是 \(y = x^2\) ,我的导数就是 \(2x\) 。
Torch 不需要知道公式,它只需要把这一路上的“局部导数”连乘起来,最终结果就是我们要的全局梯度。回忆一下高中数学的定理——链式法则 (Chain Rule)。
对于复合函数 \(y = f(g(x))\) ,如果我们令 \(u = g(x)\) ,那么:
\[
\frac{dy}{dx} = \frac{dy}{du} \cdot \frac{du}{dx}
\]
Torch 的 Autograd 系统本质上就是在这个链路中自动执行乘法运算。在深度学习框架中,每一次数学运算不仅是数值的计算,更是图结构的构建。R torch 采用的是动态计算图 (Dynamic Computational Graph),即“运行时定义 (Define-by-Run)”模式。
从图论的角度看,神经网络是一个有向无环图 \(G = (V, E)\) :
节点 (Nodes, \(V\) ):代表数据,即张量(Tensor)。
边 (Edges, \(E\) ):代表运算,即函数(Function)。
当我们执行一段 R 代码时,torch 在后台同时维护着两套逻辑:
前向逻辑 (Forward):计算数值(Data),从输入流向输出。
反向逻辑 (Backward):构建梯度函数链表,为未来的反向传播做准备。
为了实现这一机制,torch_tensor 对象在 C++ 底层维护了一个关键指针:grad_fn。
叶子节点 (Leaf Nodes):图的输入端(如权重 \(w\) 、偏置 \(b\) )。它们是用户创建的,不是由运算产生的。它们的 grad_fn 为 NULL。
中间节点 (Intermediate Nodes):由运算产生的张量(如 \(y = w \cdot x\) 中的 \(y\) )。它们持有 grad_fn,指向生成该张量的运算操作对象。
让我们通过代码,像调试器一样逐层检查这个结构。
library (torch)# 1. 定义叶子节点 # requires_grad = TRUE 是构建图的开关 # 只有开启它,torch 才会分配内存去记录后续的操作 <- torch_tensor (2.0 , requires_grad = TRUE )<- torch_tensor (5.0 , requires_grad = TRUE )<- torch_tensor (3.0 ) # 输入数据通常不需要梯度 # 2. 执行运算(构建图) # 步骤 A: 乘法 <- w * x # 步骤 B: 加法 <- u + b# 步骤 C: 平方 <- v ^ 2 # 3. 计算图结构分析:追踪 grad_fn # Level 0: 输出层 # 解释: 这是一个“幂运算”的反向函数对象 print (loss$ grad_fn)# Level 1: 中间层 # 我们可以通过 next_functions 访问图的上一层 # 注意:这是 R torch 暴露出来的底层接口,用于调试图结构 # loss 是由 v 算出来的,所以它的上一级是 AddBackward (v 的生成逻辑) print (loss$ grad_fn$ next_functions)# Level 2: 更深层 # AddBackward0 (v) 是由 u 和 b 算出来的 # 所以它的 next_functions 包含 MulBackward0 (u) 和 AccumulateGrad (b) <- loss$ grad_fn$ next_functions[[1 ]]$ next_functionsprint (v_grad_fn)
[[1]]
MulBackward0
[[2]]
torch::autograd::AccumulateGrad
在执行前向计算 loss <- v^2 的瞬间,torch 并不是只算出了 121 这个数,而是在内存中生成了一个 PowBackward0 对象,并让这个对象持有了一个指向 AddBackward0 的指针。
这一系列对象构成了一个单向链表。当我们调用 loss$backward() 时,torch 的引擎只是简单地遍历这个链表,依次调用每个节点的 Apply 方法计算偏导数。
因为是动态图,所以 R 语言的 if 或 for 可以用来改变网络结构的拓扑结构:
<- function (x, w) {if (as.numeric (x$ mean ()) > 0 ) {return (torch_log (x) * w) # 路径 A: 包含 Log 和 Mul 运算 else {return (torch_abs (x) + w) # 路径 B: 包含 Abs 和 Add 运算 <- torch_tensor (1.0 , requires_grad = TRUE )<- dynamic_op (torch_tensor (2.0 ), w) # 输入为正 $ grad_fn$ print ()<- dynamic_op (torch_tensor (- 2.0 ), w) # 输入为负 $ grad_fn$ print ()
在 R torch 中,不存在一个“固定的”全局图。每次前向传播,都是在创建一张全新的图。这虽然带来了一定的 R 运行时开销,但换来了极致的灵活性,使得处理变长序列(RNN)和图神经网络(GNN)变得符合直觉。
梯度的三部曲
在深度学习的训练循环中,梯度的生命周期遵循严格的“三部曲”:开启追踪 -> 反向传播 -> 梯度清零。
语法和使用细节
一、开启追踪 (requires_grad)
在 R torch 中,张量被创建时默认是不分配梯度内存的。这是为了最大化工程效率——输入数据(Features)和标签(Labels)通常不需要更新,如果对它们也分配梯度内存,显存占用将翻倍。
我们必须显式地声明哪些张量是“参数(Parameters)”。
# 普通数据张量 (Default) <- torch_tensor (3.0 ) # 模型参数张量 <- torch_tensor (2.0 , requires_grad = TRUE )# 或者后期原地修改 (In-place) <- torch_tensor (5.0 )$ requires_grad_ (TRUE ) 当你使用 nn_linear 或 nn_conv2d 等标准层时,torch 已经自动将其内部的 weight 和 bias 设置为了 requires_grad = TRUE。
二、反向传播(backward)
loss$backward() 是 Autograd 引擎的启动键。需要特别注意的是,这个函数没有返回值。
在 R 的常规函数中,我们习惯 grad <- calculate_grad(loss)。但在 torch 中,梯度是被“写入”到计算图叶子节点的 $grad 属性中的。
我们可以看一个例子,设函数 \(y = 3x^2 + 2\) ,当 \(x=2\) 时:
前向值:\(y = 3(2^2) + 2 = 14\)
导数(梯度):\(\frac{dy}{dx} = 6x = 6(2) = 12\)
<- torch_tensor (2.0 , requires_grad = TRUE )<- 3 * x^ 2 + 2 ) # 前向传播,打印 y
torch_tensor
14
[ CPUFloatType{1} ][ grad_fn = <AddBackward1> ]
$ backward () # 遍历计算图,计算梯度,并将结果写入 x$grad print (x$ grad) # 检查反向传播后的结果
torch_tensor
12
[ CPUFloatType{1} ]
为了让你彻底放心 torch 的数学能力,我们来看一个多元微积分例子。假设函数 \(z = x^2 + y^3\) 。我们要计算在点 \((x=2, y=3)\) 处的梯度。
理论导数:\(\frac{\partial z}{\partial x} = 2x\) ,\(\frac{\partial z}{\partial y} = 3y^2\) 。
代入数值:\(x=2 \to 4\) , \(y=3 \to 27\) 。
<- torch_tensor (2.0 , requires_grad = TRUE )<- torch_tensor (3.0 , requires_grad = TRUE )<- x^ 2 + y^ 3 $ backward ()cat ("x 的梯度 (2x -> 4): " , x$ grad$ item (), " \n " )cat ("y 的梯度 (3y^2 -> 27): " , y$ grad$ item (), " \n " )
看到代码输出精确地吻合数学推导,是不是有一种掌控感?我们完全不需要像第一节一样,将每个数学推导都来一遍,这正是“可微编程(Differentiable Programming)”的魅力所在。
三、梯度的累加机制(Accumulation)
这是 R torch 设计中最反直觉的地方。当你再次调用 backward() 时,新计算出的梯度不会覆盖旧的梯度,而是会“加”在旧梯度上。即:
\[
\text{grad}_{\text{new}} = \text{grad}_{\text{old}} + \frac{\partial L}{\partial w}
\]
可以做个小实验:
library (torch)# 定义一个变量 w = 2 <- torch_tensor (2.0 , requires_grad = TRUE )# 假设函数 y = 3 * w # 导数 dy/dw = 3 # 理论上,无论我们算多少次,导数都应该是 3 <- 3 * w # 第 1 次反向传播 $ backward ()cat ("第 1 次 backward 后,w$grad =" , w$ grad$ item (), " \n " )
第 1 次 backward 后,w$grad = 3
<- 3 * w # 第 2 次反向传播,我们没有清空梯度,直接再算一次 $ backward ()cat ("第 2 次 backward 后,w$grad =" , w$ grad$ item (), " \n " )
第 2 次 backward 后,w$grad = 6
<- 3 * w # 第 3 次反向传播 $ backward ()cat ("第 3 次 backward 后,w$grad =" , w$ grad$ item (), " \n " )
第 3 次 backward 后,w$grad = 9
但这并非设计缺陷,而是为了工程上的灵活性。假如 GPU 显存塞不下 Batch Size = 64 的数据,我们可以把数据切成 4 个 Batch Size = 16 的小块,分别 Backward,梯度会自动累加,最后 Update 一次。这等价于训练了 Batch Size = 64。
这种机制意味着,在常规的训练循环中,我们必须手动干预,显式地把梯度归零。否则,第 100 轮训练时的梯度,将包含前 99 轮所有梯度的总和,这会导致更新步长过大,模型瞬间发散。
在底层 API 中,我们需要调用张量的原地操作 zero_():
# 手动清空梯度 $ grad$ zero_ ()cat ("清空后,w$grad =" , w$ grad$ item (), " \n " )# 输出: 0
上下文管理
在 R torch 中,只要输入张量的 requires_grad = TRUE,系统就会默认你正在进行模型训练,从而不惜一切代价记录操作历史。但在验证(Validation)或预测(Inference)阶段,我们需要暂停这个机制,这就是 with_no_grad 上下文管理器的作用。 在 with_no_grad 代码块内,即便声明了张量的 requires_grad = TRUE,torch 也不会为它们构建计算图。
<- torch_randn (100 , 100 , requires_grad = TRUE )<- torch_randn (100 , 100 )# 训练模式 <- Sys.time ()for (i in 1 : 5000 ) {<- torch_matmul (w, x)Sys.time () - start_time# Time difference of 0.2006299 secs # 推断模式 <- Sys.time ()with_no_grad ({for (i in 1 : 5000 ) {<- torch_matmul (w, x)Sys.time () - start_time# Time difference of 0.06900597 secs 推断模式下不构建计算图,所以速度会更快。同 with_no_grad() 经常一起出现的还有 model$eval(),它的主要作用是改变层的数学行为:比如训练的时候有 dropout,但 eval 时就不要做 dropout 动作了。
另外,R 用户非常习惯使用 list 或者 data.frame 来存储循环中的结果,但在 torch 中会造成内存泄露。
<- list ()# 假设我们在训练循环中 for (i in 1 : 1000 ) {# Forward ... <- (w * x)^ 2 # 假设这是一个复杂的计算图终点 # [错误做法] # history[[i]] <- loss # loss 对象身上挂着整个计算图(grad_fn 链表)。 # 只要 list 引用了 loss,整个图及其所有中间变量就无法被垃圾回收(GC)。 # 跑几千轮后,内存将被撑爆。 # [正确做法 A]:只存数值 # item() 将 0-dim 张量转换为 R 的原生数值 (numeric) <- loss$ item ()# [正确做法 B]:剥离张量 # detach() 创建一个新的张量,数据共享,但切断了与图的联系 <- loss$ detach ()# history[[i]] <- detached_loss 如果你需要将 Tensor 转化为 R 的原生数据(如用于 ggplot2 绘图),或者需要将 Tensor 存起来供下一轮使用(如 RNN 的隐藏状态),务必使用 detach() 或 item()。
张量视角的模型构建
回到前面的回归参数求解的案例,我们重新用张量实现一遍。
首先我们需要定义模型参数 \(W\) 和 \(b\) ,并表达求导的意图 requires_grad = TRUE。
torch_manual_seed (123 ) # torch 的随机数种子 # 数据转换 <- torch_tensor (x_scaled, dtype = torch_float ())<- torch_tensor (y_raw, dtype = torch_float ())<- y_tensor$ view (c (- 1 , 1 )) # 转为 (N, 1) 形状 # 权重 W (形状: 2行1列) # 开启 requires_grad = TRUE,让 Autograd 记录对 W 的所有操作 <- torch_randn (c (2 , 1 ), dtype = torch_float (), requires_grad = TRUE )# 偏置 b (形状: 1) <- torch_zeros (c (1 , 1 ), dtype = torch_float (), requires_grad = TRUE )print (w) # 看下 w 长什么样
torch_tensor
-0.1115
0.1204
[ CPUFloatType{2,1} ][ requires_grad = TRUE ]
设置学习率和迭代次数
<- 0.1 <- 100
前面开启了梯度追踪,紧跟着是反向传播 loss$backward() 和梯度清零:
for (epoch in 1 : epochs) {# Forward,建立计算图:y = XW + b <- torch_matmul (x_tensor, w) + b# 计算均方误差 (MSE) <- (y_pred - y_tensor)$ pow (2 )$ mean ()# 反向传播 (Backward Pass) - Autograd # 自动计算 loss 关于 w 和 b 的梯度,并存储在 w$grad 和 b$grad 中。 $ backward ()# 参数更新 (Update Weights) # 必须在 with_no_grad() 中进行,防止更新操作被记录到计算图中 with_no_grad ({# 使用原地减法 sub_ (substract in-place) $ sub_ (learning_rate * w$ grad)$ sub_ (learning_rate * b$ grad)# 手动清空梯度!否则下一轮的梯度会叠加在这一轮的梯度上 $ grad$ zero_ ()$ grad$ zero_ ()if (epoch %% 20 == 0 ) {cat (sprintf ("Epoch: %d, Loss: %.4f \n " , epoch, loss$ item ()))
Epoch: 20, Loss: 6.2026
Epoch: 40, Loss: 6.0968
Epoch: 60, Loss: 6.0953
Epoch: 80, Loss: 6.0953
Epoch: 100, Loss: 6.0952
cat (as.numeric (b), as.numeric (w), ' \n ' )
20.09062 -3.793552 -2.179184
对比解析解、R 原生梯度下降、Torch_Autograd 三个版本的结果。
Intercept
20.090625
20.09062
20.0906
wt
-3.794292
-3.793605
-3.7936
hp
-2.178444
-2.179132
-2.1792
三种方法的计算结果基本没什么差异。
引入优化器
仔细观察上一节的代码,你会发现参数更新的步骤略显繁琐:我们需要手动通过 with_no_grad 暂停追踪,手动做减法更新,还要手动清空梯度。
# 手动更新的繁琐写法 with_no_grad ({$ sub_ (learning_rate * w$ grad)$ sub_ (learning_rate * b$ grad)$ grad$ zero_ ()$ grad$ zero_ ()如果模型有 100 层,每层都有权重和偏置,手动写这几行代码将是灾难。
R torch 提供了一个更高层的抽象——优化器 (Optimizer)。优化器本质上是一个通过“托管”参数来自动化更新流程的对象。它将上述的样板代码封装成了两个标准方法:
optimizer$step(): 替代了手动的减法更新。optimizer$zero_grad(): 替代了手动的 grad$zero_()。
让我们用 optim_sgd(随机梯度下降优化器)来重构之前的线性回归代码。你会发现,无论模型多么复杂,训练循环的代码结构永远保持不变。
<- torch_randn (c (2 , 1 ), dtype = torch_float (), requires_grad = TRUE )<- torch_zeros (c (1 , 1 ), dtype = torch_float (), requires_grad = TRUE )# 定义优化器 <- optim_sgd (params = list (w, b), lr = learning_rate)# 训练循环 for (epoch in 1 : epochs) {<- torch_matmul (x_tensor, w) + b<- (y_pred - y_tensor)$ pow (2 )$ mean ()# 1. 清空过往梯度 # 必须在 backward 之前调用,否则梯度会累加 $ zero_grad ()# 2. 反向传播 # 计算当前梯度,填入 w$grad 和 b$grad $ backward ()# 3. 执行更新 # 根据 w$grad 和学习率,自动修正 w 的值 $ step ()if (epoch %% 20 == 0 ) {cat (sprintf ("Epoch: %d, Loss: %.4f \n " , epoch, loss$ item ()))
Epoch: 20, Loss: 6.2062
Epoch: 40, Loss: 6.0970
Epoch: 60, Loss: 6.0954
Epoch: 80, Loss: 6.0953
Epoch: 100, Loss: 6.0952
cat (as.numeric (b), as.numeric (w), ' \n ' )
20.09062 -3.793497 -2.17924
这段代码展示了深度学习工程中最通用的范式。此时,optimizer 就像是一个仅仅执行命令的工兵,我们告诉它用最简单的 SGD 算法(仅仅是减去梯度)。