library(torch)
library(tidyverse)
library(gclus)
data(wine)
set.seed(42)
torch_manual_seed(42)
# 定义自定义 Dataset 类
wine_custom_dataset <- dataset(
name = "WineDataset",
initialize = function(features_matrix, labels_vector) {
# 初始化:将传入的 R 矩阵和向量转换为 Torch Tensor 存在 self 中
# 提前转换好可以避免在 .getitem 中反复转换,提高读取效率
self$x <- torch_tensor(features_matrix, dtype = torch_float32())
self$y <- torch_tensor(as.integer(labels_vector), dtype = torch_long())
},
.getitem = function(i) {
# 获取单个样本:根据索引 i 提取对应的特征和标签
# R 中的索引是从 1 开始的
x_item <- self$x[i, ]
y_item <- self$y[i]
# 将特征和标签以列表形式返回
return(list(x = x_item, y = y_item))
},
.length = function() {
# 返回数据集的总行数(样本数)
return(self$x$size(1))
}
)
# 传入 R 矩阵和向量即可,initialize 会自动完成 Tensor 转换
wine_features <- wine %>% select(-Class) %>% scale() %>% as.matrix()
my_wine_dataset <- wine_custom_dataset(features_matrix = wine_features,
labels_vector = wine$Class)5 luz 训练框架
前几章我们手写了完整的训练循环——手动管理梯度清零、反向传播、参数更新,以及训练/验证模式的切换。这套流程虽然透明,但随着模型复杂度增加,代码会变得越来越冗长且容易出错。本章聚焦一个关键的工程问题:如何高效地组织训练数据,以及如何用简洁、不易出错的方式编排整个训练流程。
下面从批量策略出发,逐步引入 torch 的 Dataset / DataLoader 体系,以及高级训练框架 luz。
5.1 批量大小的权衡
最朴素的更新公式是:
\[ w_{t+1} = w_t - \eta \cdot \nabla L(w_t) \]
其中 \(\eta\) 是学习率。但在计算 \(\nabla L\) 时,我们需要用到多少数据?
批量梯度下降 (Batch GD) 与随机梯度下降 (SGD)
Batch GD:每次更新都计算所有样本的梯度(前面章节大部分都是这个做法)。
- 做法:把所有训练数据都算一遍,求平均梯度,然后走一步。
- 优点:梯度估计准确,更新稳定。
- 缺点:内存瞬间爆炸;每次更新都要算很久,且容易卡在鞍点(Saddle Point)出不来(因为梯度太稳了,没有噪声)。
SGD:每次更新只用一个样本。
- 做法:每次只随机抽取一条数据,算梯度,走一步。
- 优点:更新频率极快,引入了大量随机噪声,有助于跳出局部最优。
- 缺点:无法利用 GPU 矩阵并行加速(GPU 讨厌处理标量);Loss 曲线剧烈震荡,难以收敛。
在这两种方法之间是否有折中方案呢?答案是肯定的——Mini-batch SGD:每次用一小批(比如 32 或 64 个)样本更新梯度。这是工业界深度学习的标准做法。每个批次的样本可以打包成一个矩阵,能充分利用 GPU 的并行优势。而且引入了适度的“梯度噪声”(Gradient Noise)。这种噪声被证明具有正则化效果,能帮助模型找到更加平坦(Robust)的极小值区域。
5.2 定义 Dataset 类
在 R 的 torch 中,我们使用 dataset() 函数来创建一个数据集类。你需要提供三个核心部分:
initialize:初始化方法,用于接收原始数据并保存到对象内部(通常在这里将数据转换为 Tensor)。.getitem:核心逻辑。当 DataLoader 抓取数据时,它会传入一个索引 i,你需要在这里返回第 i 个样本及其对应的标签。.length:告诉 DataLoader 这个数据集一共有多少个样本。
我们以 wine 数据集为例,定义一个自定义的 Dataset 类。该数据集包含 178 条葡萄酒样本、13 个连续型化学特征(酒精浓度、苹果酸、黄酮类化合物等),目标变量为 3 个类别标签。
看一下 dataset 的定义(R6 类):
有了 Dataset,我们依然只能一个一个地获取数据。在训练神经网络时,我们需要:
- Batching:将 batch_size 个样本打包成一个张量,利用矩阵运算加速。
- Shuffling:每个 Epoch 打乱数据顺序,防止模型记忆样本顺序。
dataloader() 就是负责这些工作的调度器。
wine_dataloader <- dataloader(my_wine_dataset, batch_size = 25, shuffle = TRUE)观察一下数据格式:
print(my_wine_dataset[1]) # 这会触发 .getitem(1)$x
torch_tensor
1.5143
-0.5607
0.2314
-1.1663
1.9085
0.8067
1.0319
-0.6577
1.2214
0.2510
0.3611
1.8427
1.0102
[ CPUFloatType{13} ]
$y
torch_tensor
1
[ CPULongType{} ]在实际建模之前,还需要将数据划分为训练集和验证集,以便在训练过程中监控模型的泛化表现。
set.seed(42)
n <- nrow(wine_features)
val_idx <- sample(seq_len(n), size = floor(n * 0.2))
wine_train_ds <- wine_custom_dataset(
features_matrix = wine_features[-val_idx, ],
labels_vector = wine$Class[-val_idx]
)
wine_val_ds <- wine_custom_dataset(
features_matrix = wine_features[val_idx, ],
labels_vector = wine$Class[val_idx]
)
wine_train_dl <- dataloader(wine_train_ds, batch_size = 25, shuffle = TRUE)
wine_val_dl <- dataloader(wine_val_ds, batch_size = 25, shuffle = FALSE)
注记.getitem 与 .getbatch
本节介绍的 .getitem 方法适合中小规模数据集,每次按索引逐行取样本,逻辑直观。但在推荐系统等百万级数据场景中,逐行读取会成为性能瓶颈。torch 提供了 .getbatch 替代方案,直接按索引向量批量切片,充分利用 C++ 底层的矩阵运算优势。第 6 章将在 MovieLens 数据上演示这一高性能模式。
5.3 引入 luz 包
安装 luz:
install.packages("luz")手写训练循环有几个常见的痛点:
- 需要手动管理
optimizer$zero_grad()、backward()和梯度更新,还要自己计算每个 epoch 的平均 Loss。 - 忘记把数据
$to(device)移动到 GPU,或忘记在验证阶段调用model$eval(),每个疏忽都会带来漫长的 debug。 - 反复在
model$train()和model$eval()之间切换。 - 想要实现 Early Stopping(早停)、保存验证集表现最好的模型、动态调整学习率,这些都需要额外编写大量辅助代码。
我们希望能像 dplyr 处理数据一样,将前面提到的优化方法优雅地整合进训练流程。
luz(Falbel 2025) 是一个用于 torch 的高级 API,它的名字来源于西班牙语的“光(Light)”,寓意着照亮深度学习的黑盒。它借鉴了 FastAI、Keras、PyTorch Lightning、HuggingFace Accelerate 等高级深度学习框架,以及 R 的 tidymodels。它将训练过程分解成一系列可重用的代码片段,减少了使用 torch 训练模型所需的冗长代码,有效规避了在反复调用 zero_grad()、backward() 和 step() 序列时容易出现的错误,并简化了在 CPU 和 GPU 之间迁移数据和模型的过程。luz 的设计非常灵活,它提供了一个分层 API,无论需要对训练循环进行何种级别的控制,它都能满足需求。 它就像 dplyr 之于数据处理,ggplot2 之于绘图,能让你用极其优雅的“管道”语法,完成标准化的深度学习训练。
这个框架下,原本复杂的训练循环、梯度清零、反向传播、状态切换,全部被压缩在以下三个标准化的管道中,管道通过 tidyverse 体系的 %>% 或者 R 原生管道符 |> 进行传递。
- 组装
setup() - 配置
set_hparams()和set_opt_hparams() - 训练
fit()
参数说明:
setup()可以配置 loss function,训练模型的优化器 optimizer(任意在 torch 中存在的,或者通过optimizer()函数创建的),或者传递一个训练过程中跟踪的指标列表,luz会自动在训练和验证过程中计算它们,无需手动编写数学公式。set_hparams()将模型的超参数传递给预先定义nn_module的方法initialize(),模型定义与具体参数分离。在本例中dim这个超参数会传递到前面定义的网络中。set_opt_hparams()用来传递优化器函数使用的超参数。例如,optim_sgd()可以接受参数lr指定学习率,optim_adam()则可额外配置 \(\beta_1\)、\(\beta_2\) 等动量相关参数。fit()是luz最强大的地方。当你运行这段代码时,luz在后台默默完成了以下工作:- 接受
setup()提供的模型规范,并使用指定的训练和验证 Dataloader 进行训练和验证。在训练循环中自动开启train()模式,在验证循环中自动切换到eval()模式并关闭梯度计算。 - 通过
accelerator自动检测是否有 GPU,并将数据和模型移动到正确的设备上,默认无需特殊声明。 - 提供了一个实时的、带有预计剩余时间的进度条。
- 如果在训练中途出错(比如内存不足),它会尝试安全退出并保存当前状态。
- 接受
训练结束后,fit 函数返回一个对象,它保存了所有的训练历史。
5.4 基础的训练流程
我们把 wine 数据集的特征提取为 2 维的表示,然后用这个表示来训练一个分类器。
library(luz)
supervised_bottleneck_module <- nn_module(
"WineSupervisedBottleneck",
initialize = function(dim) {
self$feature_extractor <- nn_sequential(
nn_linear(13, 64),
nn_relu(),
nn_linear(64, dim)
)
self$classifier_head <- nn_linear(dim, 3)
},
forward = function(x) {
latent_2d <- self$feature_extractor(x)
logits <- self$classifier_head(latent_2d)
return(logits)
}
)接下来是训练环节1:
1 对于分类问题(预测离散类别),最常用的是交叉熵损失(Cross-Entropy Loss)。它衡量的是预测概率分布与真实分布之间的差异。同学们可以在课后通过大模型对话,了解交叉熵损失的详细计算公式和特点,这里不做展开。
fitted_model <- supervised_bottleneck_module %>%
setup(
loss = nn_cross_entropy_loss(),
optimizer = optim_sgd
) %>%
set_opt_hparams(lr = 0.01) %>%
set_hparams(dim = 2) %>%
fit(
data = wine_train_dl,
epochs = 150,
valid_data = wine_val_dl,
callbacks = list(
luz_callback_early_stopping(patience = 5, monitor = "valid_loss")
),
# 本机有 GPU 时 luz 会自动使用 GPU,这里强制使用 CPU,避免预测时从 GPU 搬运数据报错
accelerator = accelerator(cpu = TRUE),
verbose = FALSE
)可以看一下模型的训练过程(注意 plot() 会同时展示训练集和验证集的 Loss 曲线):
plot(fitted_model)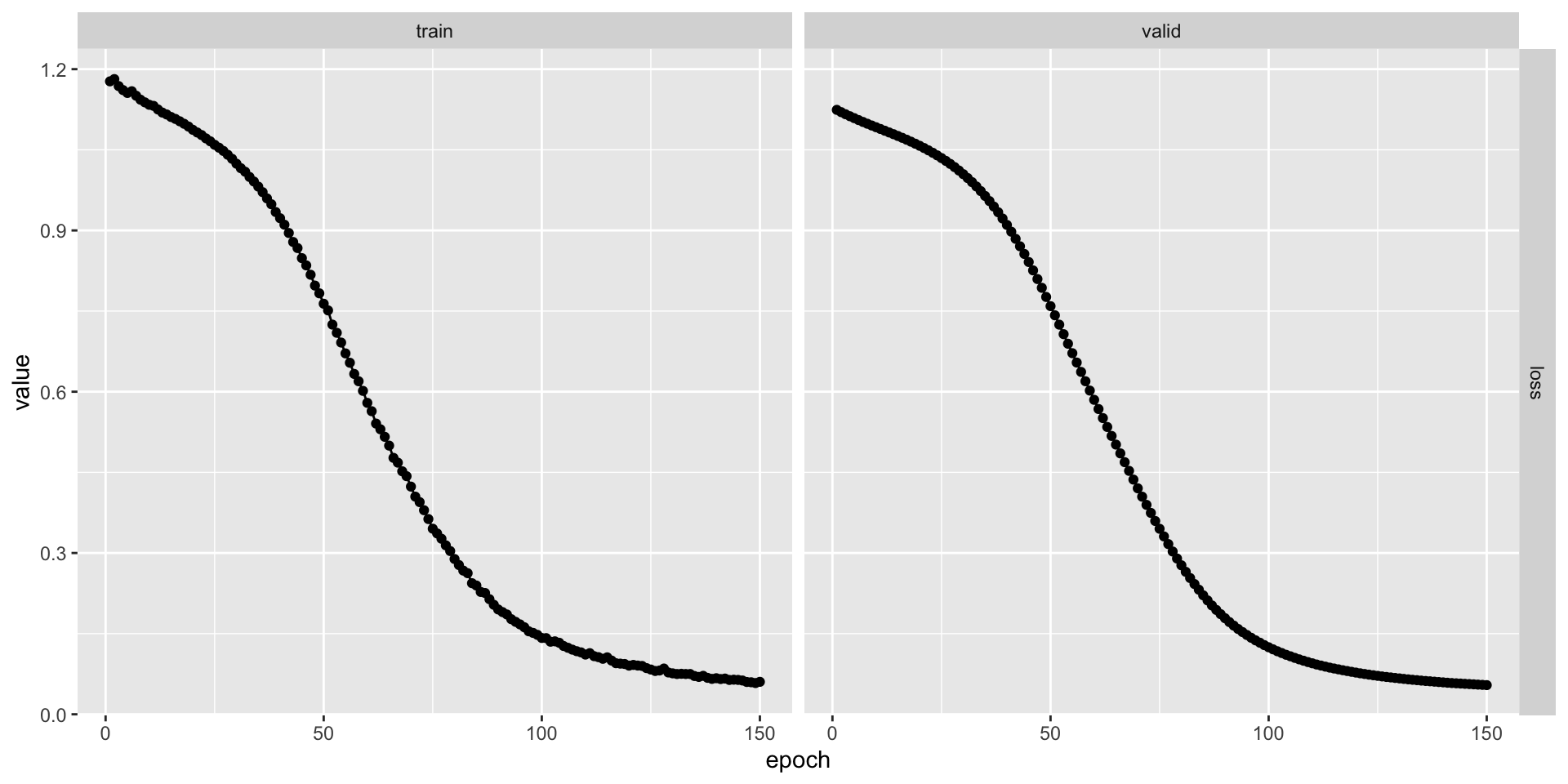
获取数据表达:
x_tensor <- torch_tensor(wine_features, dtype = torch_float32())
fitted_model$model$eval()
with_no_grad({
# 提取二维特征
latent_tensor <- fitted_model$model$feature_extractor(x_tensor)
representations <- as.matrix(latent_tensor)
# 提取最终分类预测
logits_tensor <- fitted_model$model(x_tensor)
final_predictions <- as.integer(as_array(torch_argmax(logits_tensor, dim = 2)))
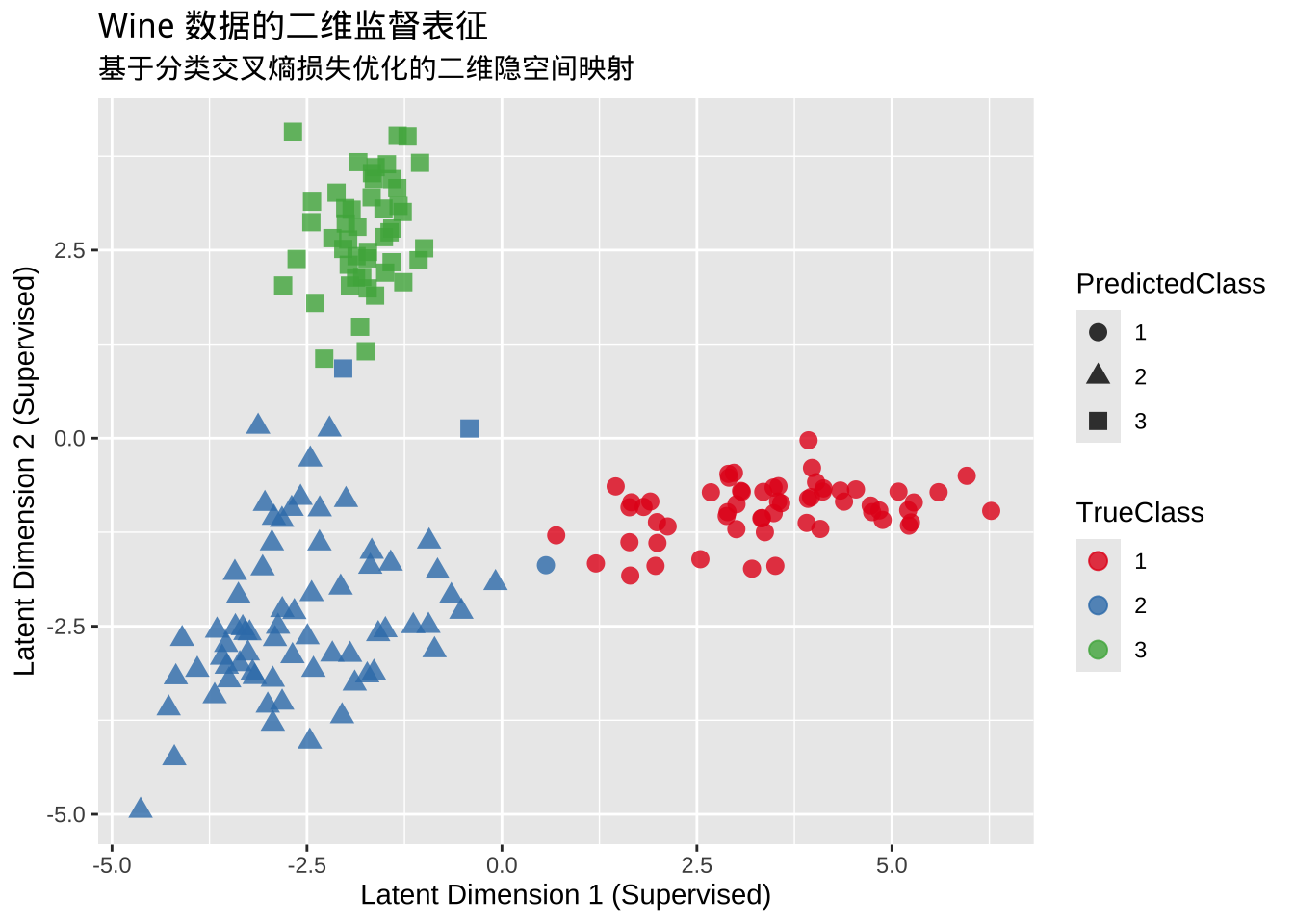
})看模型的混淆矩阵:
plot_data <- data.frame(
Dim1 = representations[, 1],
Dim2 = representations[, 2],
PredictedClass = as.factor(final_predictions), # 网络预测的类别
TrueClass = as.factor(wine$Class) # 真实的类别标签
)
table(plot_data$PredictedClass, plot_data$TrueClass)
1 2 3
1 59 1 0
2 0 68 0
3 0 2 48绘图可视化:
library(showtext)
showtext_auto()
ggplot(plot_data, aes(x = Dim1, y = Dim2)) +
# 颜色代表真实类别,形状代表网络的预测结果
geom_point(aes(color = TrueClass, shape = PredictedClass), size = 3, alpha = 0.8) +
scale_color_brewer(palette = "Set1") +
labs(
title = "Wine 数据的二维监督表征",
subtitle = "基于分类交叉熵损失优化的二维隐空间映射",
x = "Latent Dimension 1 (Supervised)",
y = "Latent Dimension 2 (Supervised)"
)
二维隐空间虽然便于可视化,但将 13 维原始特征强行压缩到 2 维,信息瓶颈过大,必然损失分类精度。下面将隐空间扩展到 5 维,保持其他配置不变(包括 Early Stopping),观察分类效果的变化:
fitted_model <- supervised_bottleneck_module %>%
setup(
loss = nn_cross_entropy_loss(),
optimizer = optim_sgd
) %>%
set_opt_hparams(lr = 0.01) %>%
set_hparams(dim = 5) %>%
fit(
data = wine_train_dl,
epochs = 150,
valid_data = wine_val_dl,
callbacks = list(
luz_callback_early_stopping(patience = 5, monitor = "valid_loss")
),
accelerator = accelerator(cpu = TRUE),
verbose = FALSE
)对比两次训练的 Loss 曲线(左:2 维,右:5 维)。5 维模型由于信息瓶颈更宽,收敛通常更快,验证 Loss 也更低:
plot(fitted_model)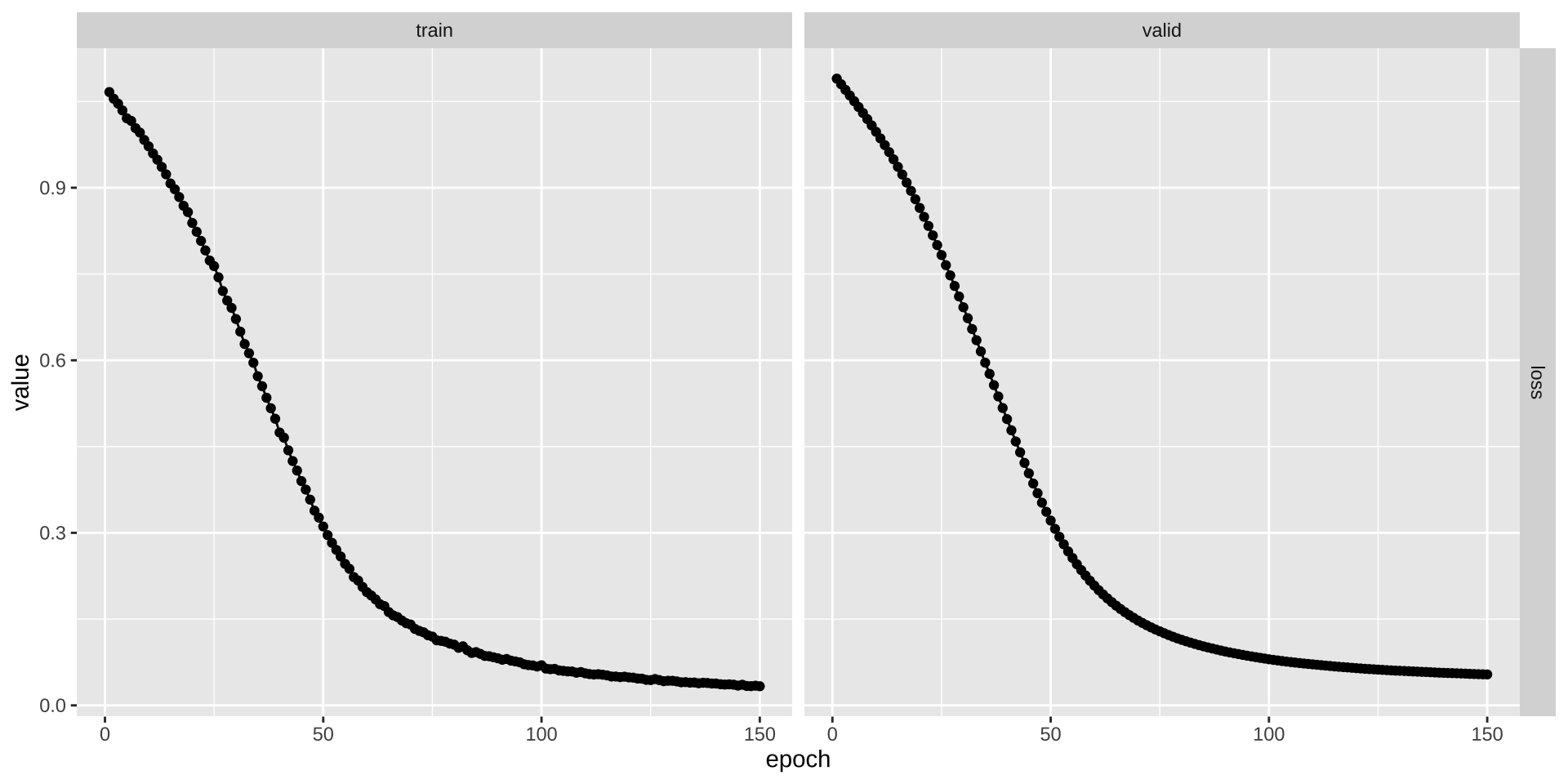
提取 5 维表征并评估分类效果:
fitted_model$model$eval()
with_no_grad({
latent_tensor <- fitted_model$model$feature_extractor(x_tensor)
representations <- as.matrix(latent_tensor)
logits_tensor <- fitted_model$model(x_tensor)
final_predictions <- as.integer(as_array(torch_argmax(logits_tensor, dim = 2)))
})看混淆矩阵,对比 2 维模型的分类效果:5 维模型的对角线通常更”干净”,误分类样本明显减少,说明适度放宽隐空间维度是平衡可视化需求与分类精度的有效手段。
table(final_predictions, wine$Class)
final_predictions 1 2 3
1 59 1 0
2 0 70 0
3 0 0 48打印前几行的 5 维向量表示:
head(representations) [,1] [,2] [,3] [,4] [,5]
[1,] 4.552976 -0.026022974 0.3356346 -1.0147437 0.77298504
[2,] 2.998512 0.079766572 0.2126660 -1.1164215 0.49903935
[3,] 3.295527 0.008792458 0.1943051 -0.7258013 0.57322240
[4,] 6.101496 -0.717174768 0.1036539 -1.2231277 1.20447254
[5,] 1.554137 0.308644533 0.1643541 -0.3100524 0.04362981
[6,] 5.084986 -0.448004276 0.2171543 -1.0493336 1.09716403本章从批量梯度下降的效率问题出发,逐步建立了 torch 的数据组织体系:
- Mini-batch 是工业界训练深度模型的标准做法,在梯度估计精度和更新效率之间取得平衡。
- Dataset + DataLoader 将数据准备与模型训练解耦,
.getitem适合中小规模数据,.getbatch则为大规模推荐场景提供了极致性能。 luz将手写训练循环中容易出错的步骤(梯度清零、模式切换、设备迁移、Early Stopping)全部自动化,通过setup()/set_hparams()/fit()三段式管道,让训练流程像dplyr处理数据一样优雅。
回顾本章的”监督瓶颈”实验:同一个网络结构,仅调整隐空间维度(2 -> 5),就能在分类精度上获得显著提升。这种”通过调整 Embedding 维度控制信息流动”的思想,正是下一章双塔模型的核心设计理念——我们将为用户和物品分别学习 Embedding,并用双塔网络将它们映射到同一个语义空间中。