欢迎来到非欧几里得空间。CNN 处理的是整齐的像素网格,而 GNN 处理的是像潘多拉森林一样复杂的图结构(Graph)。在这里,数据不再孤立,重点在于关系。就像纳美人的神经连接一样,让一个节点能够聚合邻居的信息,从而感知到整个网络的智慧。
SVD 到图卷积网络
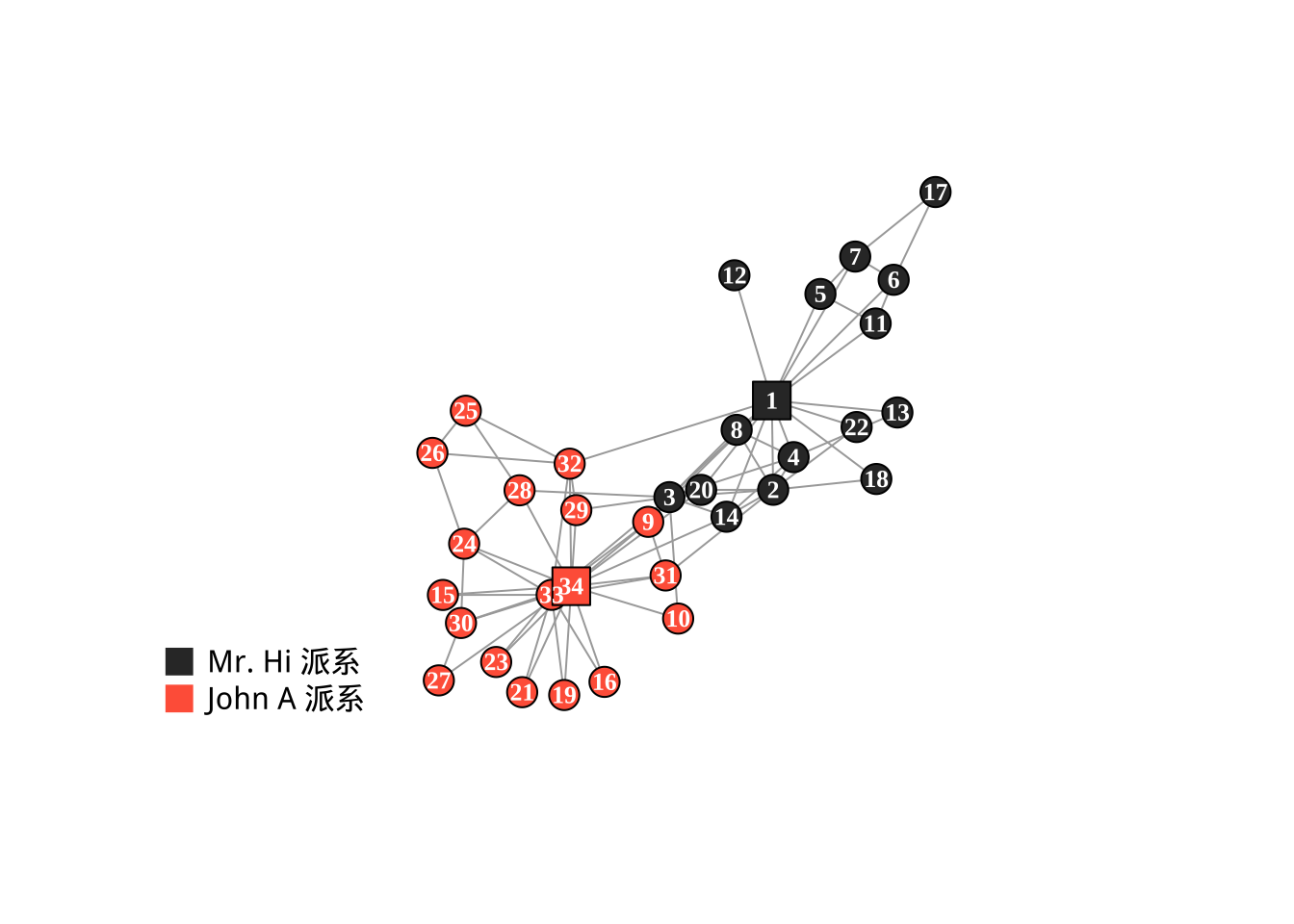
在 1970 年代初期,美国社会学家 Wayne Zachary 在美国一所大学发起了一项跆拳道社团成员社交网络研究。在观察期间,俱乐部内部爆发了激烈的政治冲突。
一方是教练(Mr. Hi):即数据集中的 Node 1。他希望提高收费,改善教学设施。
一方是主管(John A):即数据集中的 Node 34。作为 俱乐部的行政管理者,他强烈反对涨价,并试图解雇教练。
Zachary 在空手道俱乐部分裂发生之前,完整的记录了成员之间的社交关系。
节点 (Nodes):34 个。代表俱乐部的 34 名成员。
边 (Edges):78 条。代表成员之间的友谊或互动关系。
这些关系不仅仅是“谁和谁一起练空手道”,而是俱乐部之外的互动(如一起吃饭、去对方家里做客等)。通过社员们的关系来预测他们最终选择的阵营,是 Zachary 当时主要研究的方向之一。
随着矛盾激化,俱乐部最终分裂成了两个独立的组织。支持教练 Mr. Hi 的人跟随他成立了新俱乐部,支持主管 John A 的人留在了原俱乐部。
library (torch)library (igraph)library (showtext)library (torch)showtext_auto ()set.seed (42 )torch_manual_seed (42 )# --- 1. Zachary's Karate Club --- <- make_graph ("Zachary" )<- c (1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 2 , 2 , # 1-10号 1 , 1 , 1 , 1 , 2 , 2 , 1 , 1 , 2 , 1 , # 11-20号 2 , 1 , 2 , 2 , 2 , 2 , 2 , 2 , 2 , 2 , # 21-30号 2 , 2 , 2 , 2 # 31-34号 # 转换为 torch 张量 <- torch_tensor (manual_labels, dtype = torch_long ())# 我们复用之前的 labels 向量 (如果不在这里,请重新运行上一段代码的 labels 定义) <- ifelse (as.numeric (labels) == 1 , "gray20" , "tomato" )# 设置颜色 V (g)$ color <- node_colors# 设置标签颜色 (为了在深色点上能看清,设为白色或浅色) V (g)$ label.color <- "white" # 把 1号 (Mr. Hi) 和 34号 (John A) 搞得大一点,或者换个形状 # 这样一眼就能看出这两个“种子节点” V (g)$ size <- 12 # 默认大小 V (g)$ size[c (1 , 34 )] <- 15 # 首领变大 V (g)$ shape <- "circle" V (g)$ shape[c (1 , 34 )] <- "square" # 首领变成方形 # 使用 Fruchterman-Reingold 布局算法 (最经典的力导向布局) plot (g, layout = layout_with_fr (g), vertex.label.font = 2 , # 字体加粗 vertex.label.cex = 0.8 # 字体大小 # 添加图例 legend ("bottomleft" , legend = c ("Mr. Hi 派系" , "John A 派系" ), col = c ("gray20" , "tomato" ), pch = 15 , # 方块图标 pt.cex = 2 ,bty = "n" ) # 不画边框
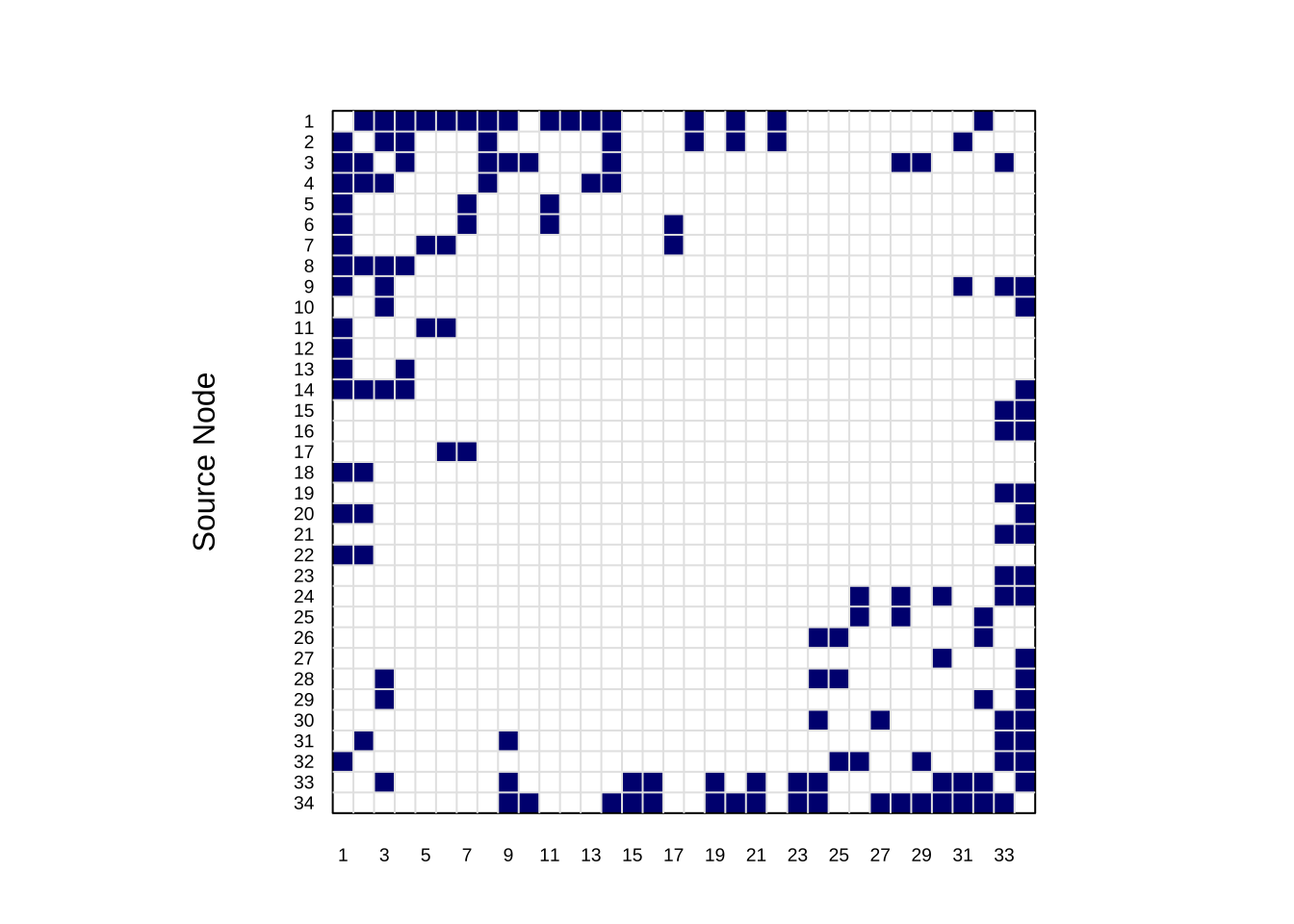
在网络中,节点间的连边关系通常被记录为边表(Edge List),例如 (1, 2), (1, 3), (1, 4)...,将其转化为矩阵形式就是判断两两关系是否存在,存在关系则记为 1,这个矩阵也被称为邻接矩阵 (Adjacency Matrix)。
<- as_adjacency_matrix (g, sparse = FALSE )<- torch_tensor (A_matrix, dtype = torch_float ())<- as.matrix (A) # 转为 R 标准矩阵 <- t (A_mat)[, ncol (A_mat): 1 ] # image() 默认是从左下角开始画的。 par (mar = c (3 , 3 , 3 , 1 ), pty = "s" ) # 设置边距和图框类型 image (1 : 34 , 1 : 34 , A_vis,# 颜色设置: 0=白色, 1=海军蓝 col = c ("white" , "navyblue" ), axes = FALSE , main = "" ,xlab = "Target Node" ,ylab = "Source Node" box ()# 添加网格线 (Grid) grid (nx = 34 , ny = 34 , col = "gray90" , lty = 1 )# X轴: 1 到 34 axis (1 , at = 1 : 34 , labels = 1 : 34 , cex.axis = 0.6 , tick = FALSE , line = - 0.5 )# Y轴: 34 到 1 (注意:因为我们翻转了矩阵,所以Y轴标签要反着标,才能对应视觉上的"从上到下") axis (2 , at = 1 : 34 , labels = 34 : 1 , cex.axis = 0.6 , tick = FALSE , las = 2 , line = - 0.5 )
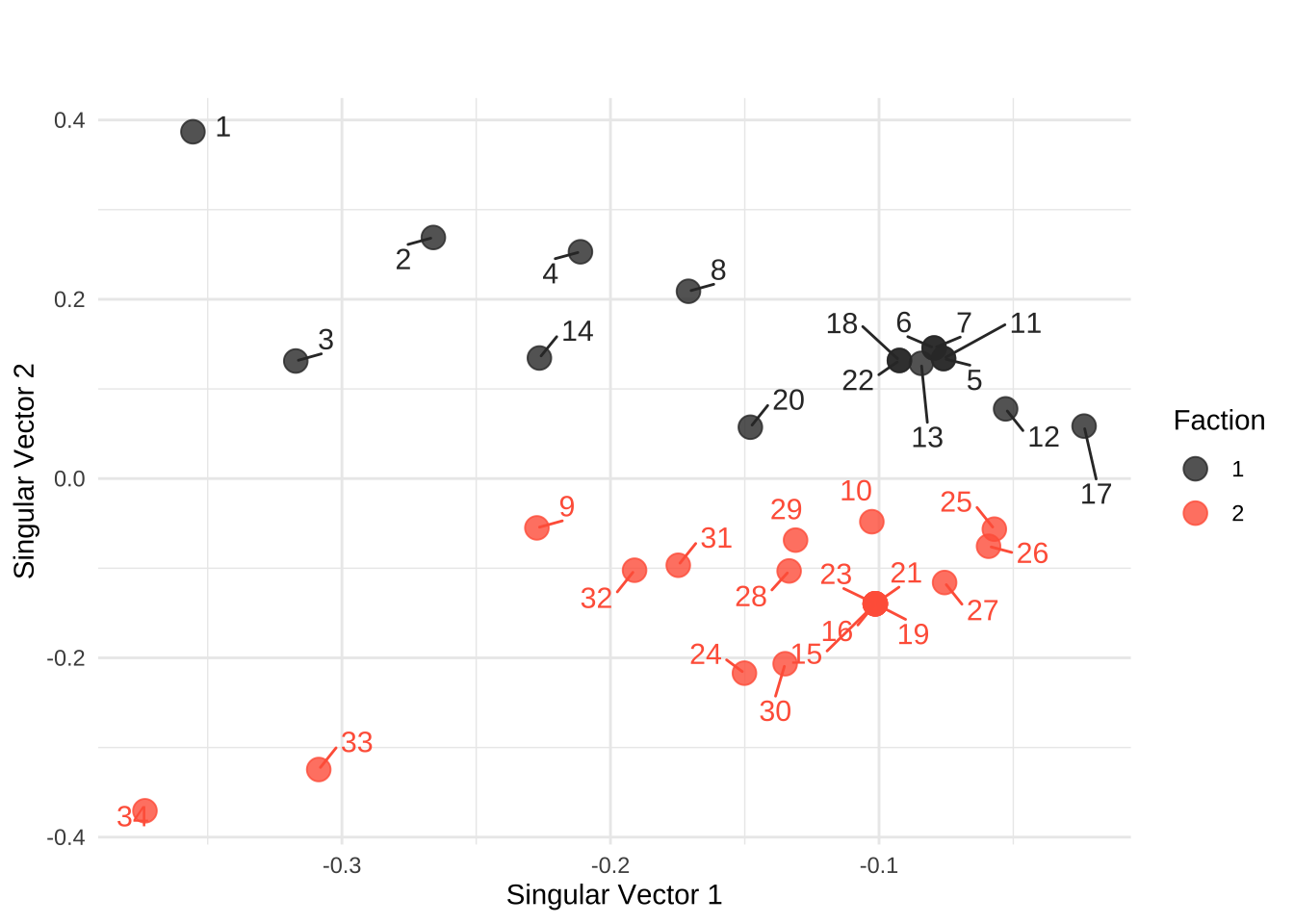
从传统统计视角看,有了这个矩阵,各个网络节点的空间表征可以通过奇异值分解 来计算获得,比如将列信息放在二维空间上,观察其远近关系。
1 注意,因为这里的邻接矩阵是对称阵,所以奇异值分解之后的行向量信息和列向量信息表达一致,分解之后 u,v 也是一样。如果是用户购买商品的协同阵,这个场景下 u,v 的意义不同。
## A 进行 SVD 分解 library (ggplot2)library (ggrepel)<- svd (as.matrix (A)) # 转为普通 matrix 计算 <- svd_res$ u[, 1 : 2 ]<- data.frame (Dim1 = svd_embeddings[, 1 ],Dim2 = svd_embeddings[, 2 ],Faction = as.factor (as.numeric (labels)), # 复用之前的标签 NodeID = 1 : 34 ggplot (df_svd, aes (x = Dim1, y = Dim2, color = Faction, label = NodeID)) + geom_point (size = 4 , alpha = 0.8 ) + geom_text_repel (size = 4 , show.legend = FALSE , max.overlaps = Inf , # 强制显示所有标签,不隐藏任何点 box.padding = 0.5 # 给标签一点额外的排斥空间 + scale_color_manual (values = c ("1" = "gray20" , "2" = "tomato" )) + theme_minimal () + labs (title = "" ,subtitle = "" ,x = "Singular Vector 1" , y = "Singular Vector 2" )
但使用奇异值分解有两个很大的弊端:
因为只用到了邻接信息,对于每个节点自己的信息无法使用。例如节点可能包含了肤色、性别、入会时间长短、缴纳会费金额数等。
SVD 是对固定的图结构做全局分解。如果我们新增或遗漏了一个节点,模型无法直接推导出它的表征,只能把整个矩阵拼在一起重新计算。而我们期望的是一个具备泛化能力的预测模型:只要掌握了节点特征和局部连接规律,任意新数据加入都能直接得出预测结果。
2 在 Zachary 最早使用“最大流最小割”算法预测时,模型将 9 划给了 Mr. Hi(因为他在那边朋友多)。但实际上,9 选择了 John A。原因是 9 马上要考黑带了,而只有 John A 才有权颁发证书——这是一种非结构性的因素。
既然 SVD 只能利用结构(邻接矩阵),而传统的神经网络全连接层只能利用属性(特征矩阵),有没有一种方法能将二者无缝融合呢?随着图卷积网络 (Kipf 和 Welling 2017 ) Graph Convolutional Network 被提出,该方法完美地将“图结构”和“神经网络”结合在了一起。它的设计思想可以拆成三个步骤:特征变换、信息聚合、归一化。
公式通常写作:
\[
H^{(l+1)} = \sigma(\underbrace{\tilde{D}^{-1/2}\tilde{A}\tilde{D}^{-1/2}}_{\text{结构归一化}} \underbrace{H^{(l)}}_{\text{特征}} \underbrace{W^{(l)}}_{\text{权重}})
\]
在 GCN 的计算中,\(H^{(l)}\) 指的是第 \(l\) 层的节点特征矩阵,而 \(H^{(l+1)}\) 则是经过特征变换、信息聚合、归一化以及非线性激活后,输出的新一层节点特征矩阵。
如果把 GCN 看作是一个节点在网络中不断“学习”的过程:
在第 0 个输入层时,\(H^{(0)}\) 其实就是原始特征矩阵 \(X\) 。而经过一层 GCN 生成的 \(H^{(1)}\) ,不仅保留了节点自身的关键特征,还浓缩了它所有邻居的特征信息。随着网络层数 \(l\) 的加深,\(H\) 包含的信息视野会越来越大,节点就能感知到更远端邻居的信息,完成在图空间中的更新(Embedding)。
我们从右向左看 GCN 到底在做什么。
第一步,\(H^{(l)}W^{(l)}\) 特征变化(神经网络):
这就是最普通的神经网络全连接层(Linear Layer)。不看图的结构,只看节点自己的特征,也被称为节点特征矩阵(Feature Matrix),矩阵的第 \(i\) 行代表第 \(i\) 个节点的特征向量。
神经网络可以把节点的特征维度进行映射(比如从 34 维降维到 4 维)。
第二步,\(\tilde{A}(H^{(l)}W^{(l)})\) 信息聚合部分:
用邻接矩阵 \(\tilde{A}\) 去乘变换后的特征矩阵。在矩阵代数中,用邻接矩阵乘特征矩阵,等同于把邻居的特征加起来。如果 \(A_{ij} = 1\) ,说明节点 \(j\) 是节点 \(i\) 的邻居,那么节点 \(j\) 的特征就会被加到节点 \(i\) 身上。
原始的 \(A\) 对角线通常是 0,为了不丢失自身信息,\(\tilde{A} = A + I\) 。
第三步,\(\tilde{D}^{-1/2}\tilde{A}\tilde{D}^{-1/2}\) 归一化:
如果一个节点有 1000 个邻居,那么特征值会非常大,我们需要加权平均,而不是简单的加和。拿一个简单的情况举例:如果我的邻居是一个超级大V(度数很高),那么他传递给我的信息权重应该被稀释(因为他的注意力分散了);如果我的邻居只有我这一个朋友,他传递给我的信息就非常重要。
有多少个邻居对应的概念就是度矩阵(degree matrix)\(D\) ,如果 \(D^{-1}A\) 只乘在左边,只解决了我是接受者的问题,我同时还是一个发送者,权重也要被平均,要右乘。从我这个节点的进出都要被控制。
对于节点 \(i\) 和 \(j\) 之间的边,权重从原本的 1 变成了 \(\frac{1}{\sqrt{d_i}\sqrt{d_j}}\) 。又因为 \(A\) 为了不丢失自身信息,加了自环,\(\tilde{A} = A + I\) ,\(\tilde{D}\) 是 \(\tilde{A}\) 的度矩阵,所以表达为矩阵 \(\tilde{D}^{-1/2}\tilde{A}\tilde{D}^{-1/2}\)
第四步,非线性激活 \(\sigma\) :
前面所有的矩阵乘法(无论是乘以邻接矩阵 \(A\) 还是权重矩阵 \(W\) ),本质上都是线性变换。如果我们在图上堆叠了多层 GCN 却不加激活函数,那么根据矩阵乘法的结合律,多层的线性叠加最终在数学上等价于单层网络,网络深度的优势将荡然无存。
套用通常的 ReLU 函数 \(f(x) = \max(0, x)\) ,非线性变换 \(\sigma\) 会将所有小于 0 的特征值“掐断”置为 0,保留大于 0 的信号。这个非线性操作赋予了模型在高维空间中扭曲和折叠特征的能力。
代码实现
首先是基础指标的计算,这里大量利用了 igraph(Antonov 等 2023 ) 包的基本功能。包括获取 Zachary 网络数据,取得邻接矩阵,绘制图形等。
library (igraph)<- make_graph ("Zachary" )<- as_adjacency_matrix (g, sparse = FALSE ) # 邻接矩阵 <- torch_tensor (A_matrix, dtype = torch_float ())<- length (V (g))<- torch_eye (num_nodes)<- A + I # 添加自环,保留自身特征 <- torch_sum (A_hat, dim = 2 ) # 计算度矩阵(按行求和) # 计算 D^{-1/2} <- torch_pow (D_hat_diag, - 0.5 )<- torch_diag (D_inv_sqrt_diag) # 将向量转回对角矩阵 # D^{-1/2} %*% A_hat %*% D^{-1/2} <- torch_mm (torch_mm (D_inv_sqrt, A_hat), D_inv_sqrt)
接下来是定义模型,是两层结构的 GCN:
<- nn_module ("GCN" ,initialize = function (in_feat, hidden_feat, out_feat) {# 两个线性层 (对应公式中的 W) $ layer1 <- nn_linear (in_feat, hidden_feat)$ layer2 <- nn_linear (hidden_feat, out_feat)forward = function (x, adj) {# 第一层 GCN <- self$ layer1 (x) # 线性变换 XW <- torch_mm (adj, x) # 向外走一步,直接的邻居 <- torch_relu (x)# 第二层 GCN <- self$ layer2 (x) # 线性变换 <- torch_mm (adj, x) # 向外走两步,邻居的邻居 return (x) # 输出层直接输出未经归一化的 Logits <- torch_eye (num_nodes) # 34x34 <- GCN (in_feat = 34 , hidden_feat = 4 , out_feat = 2 )# 真实标签 (Ground Truth): # 1 = Mr. Hi (教练), 2 = John A (主管) <- c (1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 2 , 2 , # 1-10号 1 , 1 , 1 , 1 , 2 , 2 , 1 , 1 , 2 , 1 , # 11-20号 2 , 1 , 2 , 2 , 2 , 2 , 2 , 2 , 2 , 2 , # 21-30号 2 , 2 , 2 , 2 # 31-34号 <- torch_tensor (manual_labels, dtype = torch_long ())
输入特征 (in_feat = 34):
因为这个数据集没有节点的个人特征(如年龄、身高等),代码使用了单位矩阵 (torch_eye) 作为特征 \(X\) 。这意味着每个节点的初始特征就是它唯一的 ID(One-Hot 编码)。
第一层 (layer1):
首先对特征进行线性变换(权重矩阵 \(W_0\) ),将变换后的特征与预处理好的邻接矩阵相乘。这步操作在数学上等同于:每个节点收集并聚合了它所有直接邻居的信息。最后做 relu 操作。
第二层 (layer2):
再次进行线性变换和邻接矩阵相乘。但此时节点收集了“邻居的邻居”的信息(二阶信息)。
读者也可以考虑注释掉第二层邻居的邻居这个逻辑,看看对最终预测有什么影响。
最终输出维度 out_feat = 2,代表两个阵营(Mr. Hi 和 John A)的预测分数(Logits)。接下来定义损失函数和更新机制:
# Cross Entropy 判断哪个类别的得分更高 <- nn_cross_entropy_loss ()<- optim_adam (model$ parameters, lr = 0.01 )for (epoch in 1 : 100 ) {$ zero_grad ()<- model (x = X, adj = L_sym)# 关键点:只计算两个节点的 Loss # 我们假装只知道 Node 1 (索引 1) 和 Node 34 (索引 34) 的身份 # Node 1 是教练 (类别 0), Node 34 是主管 (类别 1) <- torch_tensor (c (1 , 34 ), dtype = torch_long ())# 只取出这两个节点的预测结果和真实标签来计算误差 <- criterion (output[target_idx], labels[target_idx])$ backward ()$ step ()if (epoch %% 10 == 0 ) {cat (sprintf ("Epoch %d | Loss: %.4f \n " , epoch, loss$ item ()))
Epoch 10 | Loss: 0.8665
Epoch 20 | Loss: 0.6674
Epoch 30 | Loss: 0.5247
Epoch 40 | Loss: 0.4090
Epoch 50 | Loss: 0.2845
Epoch 60 | Loss: 0.1742
Epoch 70 | Loss: 0.1012
Epoch 80 | Loss: 0.0605
Epoch 90 | Loss: 0.0389
Epoch 100 | Loss: 0.0273
这里使用了半监督训练策略 (Semi-Supervised Learning)。虽然空手道俱乐部有 34 个人,但我们只用了 2 个人的标签来训练模型。
所有人都有真实标签,但在训练计算 Loss 时,被“人为隐藏”了。
在计算 loss 时,只传入了这两个节点的预测值(每一类的概率)和真实标签。
虽然 Loss 只由 2 个节点产生,但在计算梯度时,由于图卷积层 torch_mm(adj, x) 的存在,这两个节点的输出依赖于它们的邻居,邻居又依赖于邻居的邻居。因此,梯度会沿着图的连接结构反向传播,更新所有节点的相关权重。
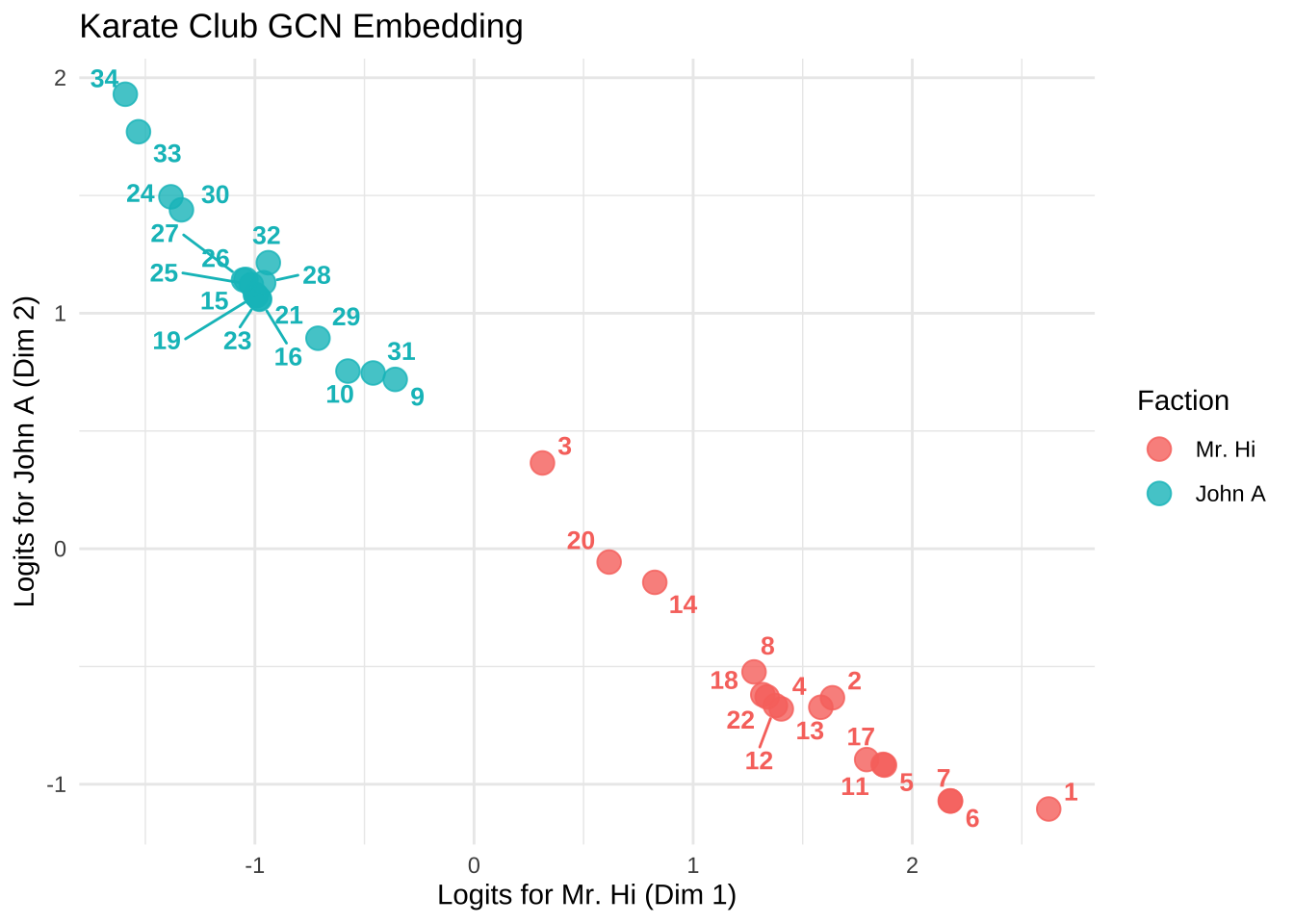
从预测结果上看,仅仅错了一个节点 3。在其他在图神经网络的研究文献中,3号节点是整个空手道俱乐部网络中最难分类的“摇摆人。当然从概率上看也是不太容易区分。
# --- 6. 结果可视化与验证 --- <- model (x = X, adj = L_sym)<- torch_argmax (final_output, dim = 2 )# 简单计算准确率 (和全部真实标签对比) data.frame (Predicted = as.numeric (predictions),True = as.numeric (labels)
Predicted True
1 1 1
2 1 1
3 2 1
4 1 1
5 1 1
6 1 1
7 1 1
8 1 1
9 2 2
10 2 2
11 1 1
12 1 1
13 1 1
14 1 1
15 2 2
16 2 2
17 1 1
18 1 1
19 2 2
20 1 1
21 2 2
22 1 1
23 2 2
24 2 2
25 2 2
26 2 2
27 2 2
28 2 2
29 2 2
30 2 2
31 2 2
32 2 2
33 2 2
34 2 2
我们将各个节点在 Mr. Hi 和 John A 两个方向上绘制散点图,同时标记实际分类,也能看到 3 很难区分:
nnf_softmax (final_output, dim = 2 )[3 ,]
torch_tensor
0.4870
0.5130
[ CPUFloatType{2} ][ grad_fn = <SliceBackward0> ]
# 1. 数据准备 <- as.matrix (final_output$ detach ())<- as.numeric (labels)<- data.frame (Dim1 = emb_mat[, 1 ], # Mr. Hi 得分 Dim2 = emb_mat[, 2 ], # John A 得分 Faction = factor (true_labels, levels = c (1 , 2 ), labels = c ("Mr. Hi" , "John A" )),NodeID = 1 : 34 # 2. 绘图 ggplot (plot_df, aes (x = Dim1, y = Dim2, color = Faction)) + geom_point (size = 4 , alpha = 0.8 ) + geom_text_repel (aes (label = NodeID),size = 3.5 ,fontface = "bold" ,box.padding = 0.3 , # 标签周围留白 point.padding = 0.3 , # 标签与点的距离 max.overlaps = Inf , # 强制显示所有标签 show.legend = FALSE + scale_color_manual (values = c ("Mr. Hi" = "#F8766D" , "John A" = "#00BFC4" )) + theme_minimal () + labs (title = "Karate Club GCN Embedding" ,x = "Logits for Mr. Hi (Dim 1)" ,y = "Logits for John A (Dim 2)"
增加特征矩阵
Zachary 空手道俱乐部数据集非常经典,但它过于简单,且不包含节点自身的属性特征。在真实世界的业务场景中,网络中的节点往往携带着丰富的信息。本节我们将引入图神经网络领域最著名的基准数据集之一——Cora 数据集,来看看当“图拓扑结构”遇上“节点特征矩阵”时,GCN 是如何发挥威力的。
Cora 数据集是一个机器学习领域的论文引用网络。在这个网络中,每一篇论文就是一个“节点”,论文之间的引用关系构成了“边”。除了引用结构,每篇论文还包含了一个 1433 维的词袋模型(Bag-of-Words)向量,用来表示特定的 1433 个关键词是否在这篇论文中出现过(出现为 1,不出现为 0),这就是我们要用到的特征矩阵 \(X\) 。
节点数 (Nodes)
2,708
数据集中共有 2708 篇机器学习论文。
边数 (Edges)
5,429
共有 5429 条引用记录。
特征维度 (Features)
1,433
每个节点是一个 1433 维的 0/1 向量(词汇表大小为 1433)。
类别数 (Classes)
7
论文被分为 7 个研究子领域。分别是:基于案例的推理、遗传算法、神经网络、概率方法、强化学习、规则学习、理论。
图类型
有向图
但在 GCN 等算法中通常被退化为无向图处理。
我们的目标是:基于这 2708 篇论文的特征和它们之间的引用关系,预测它们分别属于哪一个子领域。
加工图数据
首先,我们需要将原始的文本数据转化为 R torch 能够处理的张量。这其中涉及到邻接矩阵的构建和归一化的实现。
#| filename: 10_GCN_Cora.R library (torch)library (tidyverse)# 1. 读取 Content (节点特征与标签) # 格式: <paper_id> <word_attributes>+ <class_label> <- read.table ("cora.content" , stringsAsFactors = FALSE )<- content$ V1<- setNames (1 : length (paper_ids), paper_ids) # 将原始ID映射为 1..N 的连续索引 # 提取特征 (X) 与标签 (Y) <- as.matrix (content[, 2 : (ncol (content) - 1 )])<- content[, ncol (content)]<- as.numeric (as.factor (labels_raw))<- length (unique (labels))<- nrow (features)# 2. 读取 Cites (引用关系/边) <- read.table ("cora.cites" , stringsAsFactors = FALSE )<- id_map[as.character (cites$ V1)]<- id_map[as.character (cites$ V2)]# 过滤悬空引用 <- ! is.na (edges_source) & ! is.na (edges_target)<- edges_source[valid_idx]<- edges_target[valid_idx]在处理大规模图数据时,传统的循环遍历非常低效。在这里,我们利用 R 语言矩阵索引的强大特性,通过 cbind 将起点和终点拼接为坐标矩阵,直接对邻接矩阵 adj 进行向量化赋值:
# 3. 高效构建邻接矩阵 (Adjacency Matrix) <- matrix (0 , nrow = num_nodes, ncol = num_nodes)# 填充边 (无向图通常设为双向) cbind (edges_source, edges_target)] <- 1 cbind (edges_target, edges_source)] <- 1 接下来是整个数据预处理的核心:结构归一化。我们将上一节推导的公式 \(\tilde{D}^{-1/2}\tilde{A}\tilde{D}^{-1/2}\) 完美地映射为基础的 R 矩阵运算:
# 4. 归一化处理 (Renormalization Trick) # A_tilde = A + I (添加自环) <- adj + diag (num_nodes)# 计算度矩阵 D 的逆平方根 <- rowSums (adj_tilde)<- diag (1 / sqrt (row_sum))# 矩阵乘法计算最终的对称归一化邻接矩阵 <- d_inv_sqrt %*% adj_tilde %*% d_inv_sqrt# 转换为 Torch Tensors <- torch_tensor (features, dtype = torch_float ())<- torch_tensor (adj_norm, dtype = torch_float ())<- torch_tensor (labels, dtype = torch_long ())<- ncol (features)
带特征的 GCN
有了处理好的特征矩阵 features 和归一化邻接矩阵 adj,我们就可以搭建图卷积网络了。这里我们显式地定义了图卷积层 GCNLayer。
# 定义单层图卷积层 <- nn_module ("GCNLayer" ,initialize = function (in_features, out_features) {# 权重矩阵 W (不使用偏置项) $ linear <- nn_linear (in_features, out_features, bias = FALSE )forward = function (x, adj) {# 1. 线性变换 (XW) <- self$ linear (x)# 2. 邻接矩阵传播 (A_tilde * (XW)) <- torch_matmul (adj, support)return (output)# 定义完整的 GCN 模型 <- nn_module ("GCN" ,initialize = function (n_feat, n_hidden, n_class, dropout) {$ gc1 <- GCNLayer (n_feat, n_hidden)$ gc2 <- GCNLayer (n_hidden, n_class)$ dropout <- nn_dropout (p = dropout)forward = function (x, adj) {# 第一层: GCN -> ReLU -> Dropout <- self$ gc1 (x, adj)<- torch_relu (x)<- self$ dropout (x)# 第二层: GCN <- self$ gc2 (x, adj)# 输出层: 直接输出 Logits,交由 nnf_cross_entropy 处理 return (x)
为什么要加入 Dropout 层?
Cora 数据集的特征维度高达 1433 维,而标准的半监督训练集中通常只划分 1040 个节点作为训练样本。在如此高维且小样本的情况下,模型极其容易陷入过拟合。引入 Dropout 可以强迫模型不去死记硬背某些特定的高频词汇,而是更好地学习图结构的泛化特征。
模型训练
图神经网络的一个巨大优势在于半监督学习(Semi-Supervised Learning)。即使全网 2708 篇论文中,我们只知道其中 1040 篇论文的真实分类,GCN 依然能通过引用关系(边),将梯度沿着图结构反向传播,从而学到所有节点的表征。
set.seed (42 )<- 16 <- 0.5 <- 0.01 <- 5e-4 <- 300 # 随机抽取 1040 个节点作为训练集,其余作为测试集 <- sample (1 : num_nodes, size = 1040 ) <- setdiff (1 : num_nodes, train_indices)<- GCN (n_feat = num_features,n_hidden = hidden_units,n_class = num_classes,dropout = dropout_rate<- optim_adamw (model$ parameters, lr = learning_rate, weight_decay = weight_decay)for (epoch in 1 : epochs) {$ train ()$ zero_grad ()<- model (features, adj)# 关键点:Loss 仅仅基于 1040 个训练集节点的预测结果进行计算 <- nnf_cross_entropy ($ backward ()$ step ()经过 300 轮训练,包含特征矩阵的 GCN 模型在测试集上的准确率为 86.33%(随机数不同会有所差别)。做一个对比实验,把代码中的特征矩阵替换为单位矩阵 features <- torch_eye(nrow(content)),即废弃掉论文的词袋信息,仅仅保留网络拓扑结构,模型准确率为 82.37%,约有 3-4 个点的差异。
图的拓扑结构(引用关系)本身就蕴含了极其巨大的信息量。即便我们不看论文里写了什么词,仅仅顺着论文的引用脉络顺藤摸瓜,模型也能猜对大约 80% 的论文分类。而那 1433 维的文本特征,更多的是起到了锦上添花的作用,帮我们进一步理清了那些处于结构边缘或引用关系复杂的模糊节点。
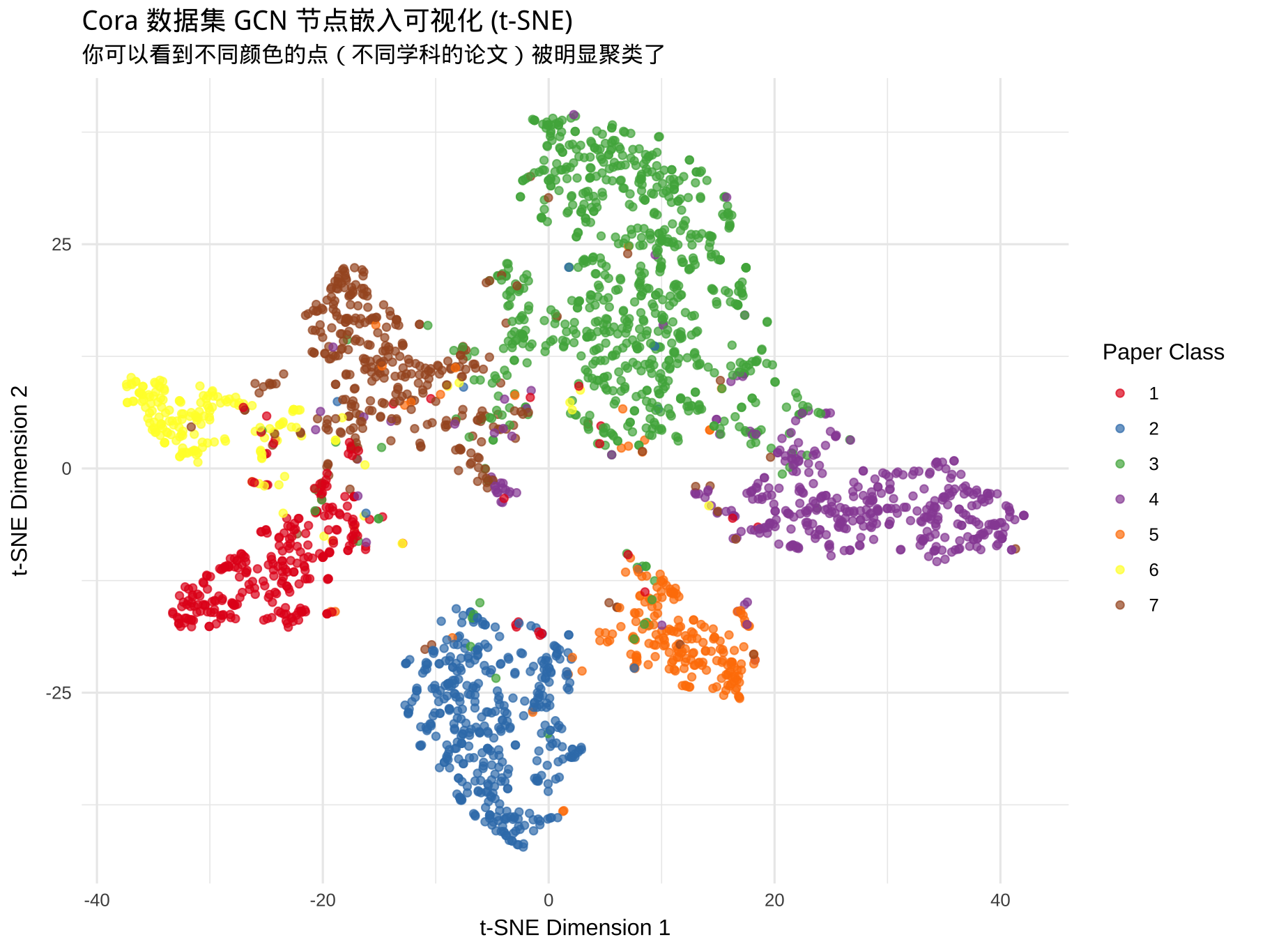
最后利用所有论文最终训练出来的 embeddings 结果,再做 t-SNE 降维可视化:
# 获取模型对所有节点的输出表征 $ eval ()<- model (features, adj)<- as_array (final_output$ detach ())# 绘图过程省略 从可视化结果中我们可以清晰地看到,原本在 1433 维空间中混杂一团的节点,在经历了两次图卷积操作后,7 个不同学科门类的论文在二维平面上形成了泾渭分明的簇状聚集。
Antonov, M., Csárdi, G., Horvát, S., Müller, K., Nepusz, T., Noom, D., Salmon, M., Traag, V., Welles, B. F., 和 Zanini, F. (2023),
《igraph enables fast and robust network analysis across programming languages》 ,
arXiv preprint arXiv:2311.10260 .
https://doi.org/10.48550/arXiv.2311.10260 .