flowchart LR
%% 样式定义
classDef init_emb fill:#fce4ec,stroke:#f06292,stroke-width:2px;
classDef hidden_emb fill:#e3f2fd,stroke:#64b5f6,stroke-width:2px;
classDef agg_op fill:#fff9c4,stroke:#fbc02d,stroke-width:2px,shape:circle;
classDef final_emb fill:#c8e6c9,stroke:#4caf50,stroke-width:2px;
classDef score fill:#ffe0b2,stroke:#ff9800,stroke-width:2px;
subgraph layer0 ["0-Hop: 初始特征"]
U_ID[User ID] --> E0_U[e_u^0]
I_ID[Item ID] --> E0_I[e_i^0]
end
subgraph layer1 ["多跳图卷积 (GCN)"]
E0_I --> E1_U[e_u^1]
E0_U --> E1_I[e_i^1]
E1_I --> E2_U[e_u^2]
E1_U --> E2_I[e_i^2]
E2_U -.-> EK_U[e_u^K]
E2_I -.-> EK_I[e_i^K]
end
subgraph layer2 ["层聚合 (Readout)"]
E0_U --> Sum_U((Sum / Mean))
E1_U --> Sum_U
E2_U --> Sum_U
EK_U --> Sum_U
E0_I --> Sum_I((Sum / Mean))
E1_I --> Sum_I
E2_I --> Sum_I
EK_I --> Sum_I
end
subgraph layer3 ["打分预测 (Predict)"]
Sum_U --> Final_U[e_u]
Sum_I --> Final_I[e_i]
Final_U --> DotProduct{内积}
Final_I --> DotProduct
DotProduct --> Score((y_ui))
end
%% 应用样式
class E0_U,E0_I init_emb;
class E1_U,E1_I,E2_U,E2_I,EK_U,EK_I hidden_emb;
class Sum_U,Sum_I agg_op;
class Final_U,Final_I final_emb;
class DotProduct,Score score;
8 GCN 的扩展应用
8.1 lightGCN
前面两个案例的只是为了演示图神经网络的思想而设置的超小型数据集,我们回归到稍稍工业化一点的场景,边规模达到百万级别的电影推荐。 上一章提到的基线算法 Standard Item-CF,在 Leave-One-Out 评估策略下,测试集上的 HR@10 基线为 0.6445。
通过前文描述,如果我聚合了周围的节点信息,将邻接矩阵做对称归一化 \(\tilde{D}^{-1/2}\tilde{A}\tilde{D}^{-1/2}\),可以有效压制热门节点的噪声,放大长尾节点的特征。我们可以尝试在 Item-CF 基础上做改进,进行多跳(Hop)传播:
A <- S_cosine
diag(A) <- 1 # 添加自环 (Self-loops)
# 计算度矩阵 D 并进行对称归一化
d_vals <- rowSums(A)
d_inv_sqrt <- 1 / sqrt(d_vals)
d_inv_sqrt[is.infinite(d_inv_sqrt)] <- 0
D_mat <- Diagonal(x = d_inv_sqrt)
A_hat <- D_mat %*% A %*% D_mat
# GNN 聚合扩散 (以 K=2 为例)
K <- 2
E_layer <- R_train
Pred_matrix_gnn <- E_layer
for (k in 1:K) {
E_layer <- E_layer %*% A_hat
Pred_matrix_gnn <- Pred_matrix_gnn + E_layer
}
Pred_matrix_gnn <- Pred_matrix_gnn / (K + 1)在这个增强版的 GNN-Enhanced CF 下,HR@10 提升到了 0.6772,效果有明显提升!这证明了捕获“邻居的邻居”这种高阶协同信息是非常有价值的。
8.1.1 思想和设计哲学
当我们将推荐数据视为一个“用户-物品”的二部图时,GCN 可以帮我们找到统一空间下 user 和 item 的向量,向量相似度代表了空间上的距离远近。标准的 GCN 包含特征变换(\(W\))和非线性激活(\(\sigma\)),但协同过滤场景的输入通常只是 ID 的 One-hot 编码,这些操作徒增了计算量,甚至可能引入过拟合。
观察原始公式:
\[ H^{(l+1)} = \sigma(\tilde{D}^{-1/2}\tilde{A}\tilde{D}^{-1/2} H^{(l)} W^{(l)}) \]
会发现,标准 GCN 包含两个对推荐任务多余的操作:
- 特征变换(Feature Transformation):即公式中的 \(W\)。因为协同过滤场景的输入通常只是 ID 的 One-hot 编码,并没有丰富的语义特征,线性变换 \(W\) 徒增了计算量,甚至可能引入过拟合。
- 非线性激活(Non-linear Activation):即公式中的 \(\sigma\)(如 ReLU)。在协同过滤场景下,非线性变换对提升效果贡献甚微,甚至会阻碍梯度的传播。
LightGCN (He 等 2020) 提出了一种极简的图卷积网络,它去掉了特征变换和非线性激活,只保留了 GCN 中最核心的组件:邻居聚合(Neighborhood Aggregation)。其单层传播公式简化为:
\[ e_u^{(k+1)} = \sum_{i \in \mathcal{N}_u} \frac{1}{\sqrt{|D_u|} \sqrt{|D_i|}} e_i^{(k)} \]
这意味着,用户在第 \(k+1\) 层的特征,仅仅是其交互过的所有物品在第 \(k\) 层特征的加权和(反之亦然)。
LightGCN 的另一个特点是对不同层 Embedding 的利用。
- 0 层(0-Hop):仅代表 ID 自身的初始特征(类似传统 MF)。
- 1 层(1-Hop):代表用户的直接交互历史(User \(\to\) Item)。
- 2 层(2-Hop):代表“和我买过一样东西的人也买过的东西”(User \(\to\) Item \(\to\) User)。
- 3 层(3-Hop):进一步捕获社群兴趣(User \(\to\) Item \(\to\) User \(\to\) Item)。
最终的输出 Embedding 是所有层 Embedding 的加权和(通常取平均):
\[ e_u = \frac{1}{K+1} \sum_{k=0}^K e_u^{(k)} \]
这种设计让 Embedding 既保留了自身的特质,又平滑了邻居的共性。
架构示意图:
8.1.2 代码实现
先看 lightGCN 函数的初始化部分
LightGCN <- nn_module(
"LightGCN",
initialize = function(num_nodes, emb_dim, n_layers) {
self$n_layers <- n_layers
self$embedding <- nn_embedding(num_nodes, emb_dim)
nn_init_normal_(self$embedding$weight, std = 0.1)
},
forward = function(adj) {
E_current <- self$embedding$weight
E_final <- E_current
# 线性图传播
for (i in 1:self$n_layers) {
E_current <- torch_mm(adj, E_current)
E_final <- E_final + E_current
}
# 层平均
return(E_final / (self$n_layers + 1))
},
score_pairs = function(all_embs, u_indices, i_indices) {
# 计算用户和物品 Embedding 的内积得分
torch_sum(all_embs[u_indices, ] * all_embs[i_indices, ], dim = 2)
}
)在训练时,邻接矩阵全图被构建为稀疏张量(Sparse Tensor)传入1。在模型更新参数的过程,我们采用了 BPR Loss(贝叶斯个性化排序损失),配合均匀负采样策略。增加一个辅助函数,通过点积来计算用户对商品的评分。
1 同理 Matrix 包里面的稀疏矩阵,只在有值的地方记录,无值的地方为空。稀疏张量利用 torch_sparse_coo_tensor 函数生成。需要注意的是,稀疏张量目前对 Mac 的 MPS 硬件加速后端支持较差,如果在 M 系列芯片的 Mac 上运行报错,建议将 device 回退至 CPU 进行矩阵乘法计算。
BPR 的核心思想是:用户对已交互物品(正样本)的偏好程度,应当高于未交互物品(负样本)。我们最大化正负样本得分之间的差值,BPR loss 定义:
\[ Loss_{BPR} = -\frac{1}{N} \sum \log \sigma(\hat{y}_{u,i} - \hat{y}_{u,j}) \]
- \(\hat{y}_{u,i} - \hat{y}_{u,j}\):如果模型很聪明,正样本得分比负样本高很多,差值就是一个很大的正数;如果模型现在还很笨(比如把没买过的商品打分打得比买过的高),差值就是负数。
- Sigmoid 函数: \(\sigma(x)\) 会把这个差值压缩到 0 到 1 之间的概率值。差值越大,结果越接近 1;差值越小(负得越多),结果越接近 0。
- 最后的负 log:\(\log(\to 0)\) 会变成一个极大的负数。带上前面的负号,就变成了一个极大的正数,即 Loss 爆表。
同时增加 L2 正则化,防止过拟合:
\[ Loss_{Reg} = \frac{1}{2} (||e_u||^2 + ||e_i||^2 + ||e_j||^2) \]
对应的更新代码为:
model <- LightGCN(num_nodes, EMB_DIM, n_layers = LAYERS)$to(device = device)
optimizer <- optim_adam(model$parameters, lr = LR)
train_u_all <- torch_tensor(dt_train_pos$user_node_id, dtype = torch_long())
train_i_all <- torch_tensor(dt_train_pos$item_node_id, dtype = torch_long())
num_edges <- nrow(dt_train_pos)
num_batches <- ceiling(num_edges / TRAIN_BATCH_SIZE)
for (epoch in 1:EPOCHS) {
model$train()
total_bpr_loss <- 0
perm_indices <- sample.int(num_edges)
for (i in 1:num_batches) {
start_idx <- (i - 1) * TRAIN_BATCH_SIZE + 1
end_idx <- min(i * TRAIN_BATCH_SIZE, num_edges)
batch_idx <- torch_tensor(perm_indices[start_idx:end_idx], dtype = torch_long())
pos_u <- train_u_all[batch_idx]$to(device = device)
pos_i <- train_i_all[batch_idx]$to(device = device)
neg_i <- torch_randint(low = num_users + 1, high = num_nodes + 1,
size = c(length(batch_idx)),
device = device, dtype = torch_long())
optimizer$zero_grad()
all_embs <- model(adj_sparse)
pos_scores <- model$score_pairs(all_embs, pos_u, pos_i) # 正样本得分
neg_scores <- model$score_pairs(all_embs, pos_u, neg_i) # 负样本得分
bpr_loss <- -torch_mean(nnf_logsigmoid(pos_scores - neg_scores)) # BPR Loss
## L2 正则化,防止过拟合
E0 <- model$embedding$weight
reg_loss <- (E0[pos_u, ]$norm(p=2)^2 + E0[pos_i, ]$norm(p=2)^2 + E0[neg_i, ]$norm(p=2)^2) / 2
loss <- bpr_loss + L2_DECAY * (reg_loss / length(batch_idx))
loss$backward()
optimizer$step()
total_bpr_loss <- total_bpr_loss + bpr_loss$item()
}
if (epoch %% 10 == 0 || epoch == 1) {
cat(sprintf("Epoch %02d/%d | Avg BPR Loss: %.4f\n",
epoch, EPOCHS, total_bpr_loss / num_batches))
}
}经过 50 个 Epoch 的训练(Embedding 维度设为 128,2 层卷积),我们可以得到以下对比结果:
| 模型 | HR@10 | 特点和现象 |
|---|---|---|
| Standard Item-CF | 0.6445 | 无参数学习,效果直观,但只能捕捉显式的共现,稀疏数据不友好。 |
| GNN-Enhanced CF (2-Hop) | 0.6772 | 无参数学习,通过对称归一化压制热门节点,平滑图结构,高阶协同有效。 |
| LightGCN (BPR Loss, emb_dim=128) | 0.7714 | 参数化学习图结构,剥离非线性变换,完美捕获高阶图语义,大幅度领跑。 |
从结果可以看出,LightGCN 取得了绝对领先的命中率 (0.7714),甚至远高于上一章完胜的双塔模型。它以极简的结构证明了:在没有丰富内容特征的场景下,图结构本身就是最好的特征。
8.1.3 工程应用
在传统的矩阵分解(MF)模型中,用户向量(User Embedding)通常被视为模型的一个静态参数。这意味着,当用户在系统中有新的交互(例如刚刚点击了一部电影),或者一个全新的冷启动用户进入系统时,模型往往束手无策——因为它必须等待下一次全量重新训练才能更新该用户的向量参数。
但在图神经网络(特别是 LightGCN)的框架下,我们拥有了处理这一问题的天然优势。这种技术在工业界常被称为 Folding-in 或 归纳式推断(Inductive Inference)。
核心思想:用户即其行为的总和。
我们在前文中提到,LightGCN 的核心传播公式本质上是邻居的线性加权平均(LightGCN 方法去掉了非线性激活函数)。如果我们忽略掉复杂的层级归一化系数,第一层图卷积可以被简单理解为:
\[ e_u \approx \text{Pool}( \{e_i | i \in \mathcal{N}_u\} ) \]
即:用户的特征向量,等于他所交互过的所有物品特征向量的聚合(通常是平均值或加权和)。
与传统 Item-CF 不同的是,Item-CF 聚合的是离散的物品 ID(拼图式的硬匹配),而 GNN 聚合的是经过训练的、包含丰富图结构信息的物品 Embedding(调色式的语义融合)。只要物品的 Embedding 训练得足够好(捕获了物品间的共现和语义关系),我们就可以通过“组装”这些物品向量,实时构建出用户的意图向量。
在工程落地实时召回时,我们通常采用“动静分离”的简化策略:
\[ e_u^{\text{realtime}} \approx \underbrace{e_u^{(0)}}_{\text{离线训练好的长期画像}} + \beta \cdot \underbrace{\text{Mean}(e_{new\_items})}_{\text{实时行为带来的增量}} \]
甚至在很多简化的 GNN 召回系统中,直接用 Item 的平均向量(Mean of Items)来代表用户当前的 Query 向量,效果已经非常好了。
8.2 分子水溶性预测
在制药与精细化工领域,分子的水溶性(Solubility)是决定研发成败的核心指标之一。它直接影响药物在生物体内的吸收、运输与药效释放。
传统上,确定分子溶解度依赖于昂贵的实验室合成与物理测量。那么,能否跳过漫长的实验过程,仅凭分子的化学结构式就预判其溶解能力?我们将这一挑战定义为一个典型的图回归(Graph Regression)任务:
- 输入 (Input):由 SMILES 字符串转化的分子图。
- 目标 (Output):预测连续数值 \(LogS\)(数值越大,溶解性越强)。
本实验采用经典的 ESOL 数据集 (Delaney 2004) 进行模型验证。该数据集包含 1128 个分子样本,每个样本都提供了分子的 SMILES 表示式以及对应的实验测得水溶性值 (LogS)。由于数据集规模适中、标注可靠,它常被用作分子性质预测的基准测试数据。
8.2.1 分子图的特征工程
分子天然具备图 (Graph) 的拓扑属性:原子即节点,化学键即边。这样的表示方式不仅符合化学直觉,也为图神经网络提供了天然的输入结构。
在化学信息学中,最通用的分子表示法是 SMILES(简化分子线性输入规范)。它将复杂的二维或三维分子结构浓缩为一行 ASCII 字符串。例如,苯酚的 SMILES 表示为 c1ccccc1O。在 R 语言体系下,我们可以借助 rcdk 包 (Guha 2007) 将 SMILES 文本解析为分子对象,并进一步转化为图结构。
为了让模型能够“读懂”化学规律,我们需要为每个节点(原子)注入多维度的微观信息。这些特征不仅定义了原子的物理状态,更隐含了分子形成氢键的能力及其极性强弱。具体包括:
- 原子身份:元素种类(C, N, O…)的 One-hot 编码。
- 物理属性:形式电荷、隐式氢原子数、节点度数。
- 空间形态:杂化态(\(sp, sp^2, sp^3\))、是否在环中、是否具备芳香性。
在代码实现中,我们可以通过 rcdk 提供的接口函数直接提取这些信息:
#| filename:10_chem_GCN.R
# 提取原子特征,包括杂化态、环信息和芳香性
for (i in seq_len(n_atoms)) {
a <- atoms[[i]]
# 元素 One-hot
atomic_num <- get.atomic.number(a)
idx <- match(atomic_num, allowed_elements)
if (is.na(idx)) idx <- length(allowed_elements) + 1
x_base[i, idx] <- 1
# 电荷、氢原子数
x_base[i, 11] <- get.formal.charge(a)
x_base[i, 12] <- get.hydrogen.count(a)
# 杂化态
hyb <- get.hybridization(a)
hyb_idx <- match(hyb, c("SP1", "SP2", "SP3"))
if (!is.na(hyb_idx)) x_base[i, 13 + hyb_idx] <- 1
# 环信息与芳香性
x_base[i, 17] <- ifelse(is.in.ring(a), 1, 0)
x_base[i, 18] <- ifelse(is.aromatic(a), 1, 0)
}通过这样的特征设计,分子图不仅包含了拓扑结构,还融合了化学语义,使得后续的图神经网络能够更好地捕捉分子性质与结构之间的关系。
8.2.2 模型结构
为了追求极致的预测精度,本章采用了一种微观拓扑 + 宏观规律的“双流融合”架构。

一、图卷积层 (GCN Layers)
- 逐层聚合邻居原子的特征,更新每个节点的表示。
- 使用度归一化,避免高连接原子主导信息。
- 多层堆叠后,节点特征逐渐包含更大范围的分子结构信息。
BatchedGCNLayer <- nn_module(
"BatchedGCNLayer",
initialize = function(in_features, out_features) {
self$W <- nn_linear(in_features, out_features, bias = FALSE)
self$bias <- nn_parameter(torch_zeros(out_features))
},
forward = function(h, adj) {
degree <- adj$sum(dim = 3, keepdim = TRUE)
degree_inv <- 1.0 / torch_clamp(degree, min = 1e-5)
adj_norm <- adj * degree_inv
support <- self$W(h)
output <- torch_bmm(adj_norm, support) + self$bias
return(output)
}
)
MaskedDualReadout <- nn_module(
"MaskedDualReadout",
initialize = function() {},
forward = function(h, mask) {
mask_expanded <- mask$unsqueeze(3)$expand_as(h)
h_masked <- h * mask_expanded
# --- Mean Pooling ---
sum_h <- h_masked$sum(dim = 2)
num_atoms <- mask$sum(dim = 2, keepdim = TRUE)$clamp(min = 1)
mean_h <- sum_h / num_atoms
# --- Max Pooling ---
max_h <- h_masked$max(dim = 2)[[1]]
# 将 Mean 和 Max 拼接 (维度翻倍)
return(torch_cat(list(mean_h, max_h), dim = 2))
}
)二、图读出层 (Graph Readout)
- 将所有节点的特征压缩为一个分子向量。
- 采用 Mean Pooling + Max Pooling 双重池化,既保留平均趋势,又保留极端特征。
三、全局特征融合 (Late Fusion)
- 除了分子图,还提取了分子量、拓扑极性表面积 (TPSA) 等全局物理特征。
- 将分子图向量与全局特征拼接,再经过全连接层预测最终的 LogS。
GraphPredictor <- nn_module(
"GraphPredictor",
initialize = function(in_dim, hidden_dim, num_global_features = 2) {
self$gcn1 <- BatchedGCNLayer(in_dim, hidden_dim)
self$gcn2 <- BatchedGCNLayer(hidden_dim, hidden_dim)
self$gcn3 <- BatchedGCNLayer(hidden_dim, hidden_dim)
self$readout <- MaskedDualReadout()
graph_emb_dim <- hidden_dim * 2
total_dim <- graph_emb_dim + num_global_features
self$bn <- nn_layer_norm(total_dim)
self$fc1 <- nn_linear(total_dim, hidden_dim)
self$fc2 <- nn_linear(hidden_dim, 1)
self$relu <- nn_relu()
self$dropout <- nn_dropout(0.2)
},
forward = function(inputs) {
h <- self$relu(self$gcn1(inputs$x, inputs$adj))
h <- self$relu(self$gcn2(h, inputs$adj))
h <- self$relu(self$gcn3(h, inputs$adj))
h_graph <- self$readout(h, inputs$mask)
h_combined <- torch_cat(list(h_graph, inputs$global_x), dim = 2)
h_combined <- self$bn(h_combined)
out <- self$relu(self$fc1(h_combined))
out <- self$dropout(out)
out <- self$fc2(out)
return(out)
}
)8.2.3 训练与效果
我们使用 ESOL 数据集进行训练,采用 MSE 损失函数。
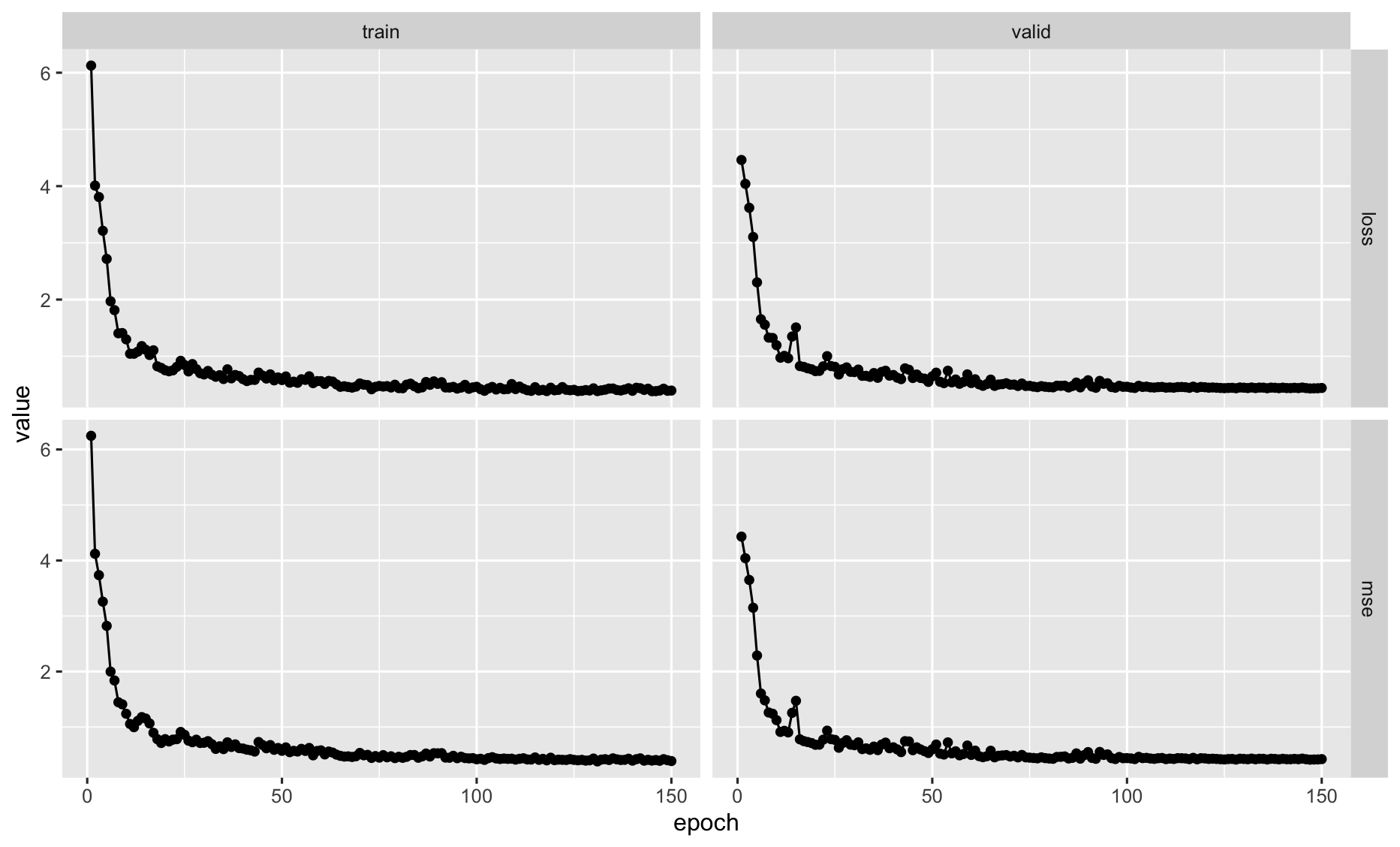
模型在验证集上的均方误差 (MSE) 收敛到 0.43 左右,对应平均预测误差约 0.65 LogS 单位,这一精度已具备很高的实战参考价值。
更令人欣慰的是,模型表现出了极强的“化学常识”。以下是模型对未知分子的实战预测结果:
- 布洛芬:难溶,预测 LogS -3.03
- 尿酸:极难溶,预测 LogS -1.00
- 甘露醇:易溶,预测 LogS 0.84
- 乙醇:与水互溶,预测 LogS 0.80
通过对布洛芬、尿酸、甘露醇和乙醇的实战测试,我们可以看到该模型在处理极性差异巨大的分子时表现出了极强的鲁棒性。这种稳定性很大程度上归功于我们将宏观物理描述符(Mass 与 TPSA)与微观图特征进行的特征融合。当 GNN 在处理某些罕见拓扑结构感到“困惑”时,全局物理特征起到了关键的数值锚定作用。
注记
布洛芬难溶于水,但其悬混液通过“微粉化”实现了物理悬浮而非化学溶解,并辅以表面活性剂解决界面适配。这种工程手段确保了微粒在瓶中稳定且不沉降,而在进入肠道高 pH 环境后能迅速释放吸收。